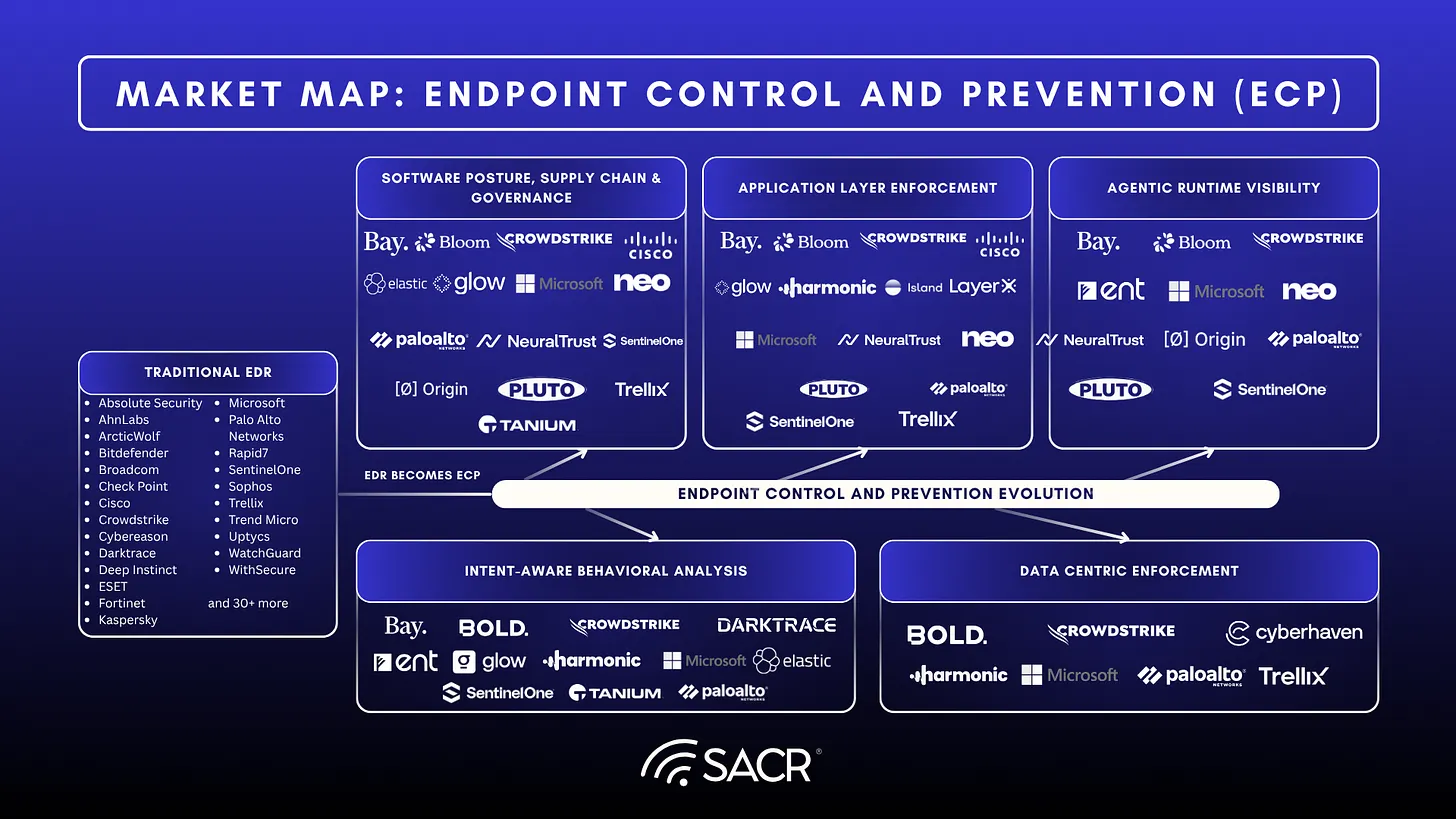
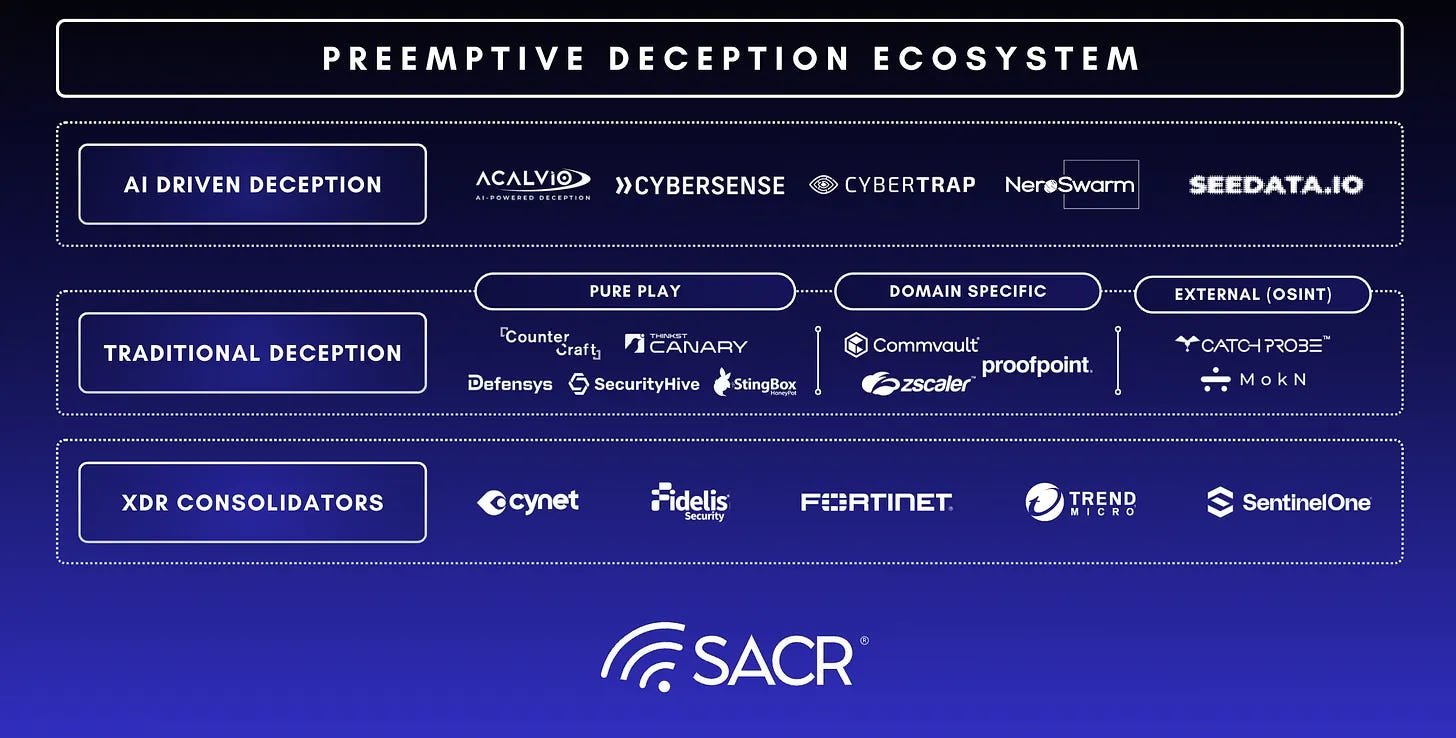
Executive Summary
The primary challenge facing security operations is the operational tempo mismatch, where attackers move at machine speed while defenders are limited by human processes, manual context assembly, and high-latency approvals. The bottleneck is not alert volume, but the effort required to create a decision-grade case from fragmented data across identity, endpoint, and cloud systems. This problem is intensified by generic detections that lack organizational context, forcing analysts to manually reconstruct the severity and scope of every alert.
AI-augmented attack workflows also change the detection problem. The defender must identify, interpret, and act on fast-changing behavior while the adversary can generate variants, test paths, and adapt around static logic. Detection programs therefore need the same speed shift that Mythos and other security centric models give vulnerability management. Continuous validation, local context, adaptive detection engineering, and agentic investigation that turns emerging activity into evidence-supported cases. The long-term direction is an operating model in which AI helps defenders detect, test, prioritize, and contain at the same tempo attackers can experiment and move.
Existing security architectures exacerbate the issue by optimizing for signal surfacing rather than decision support. Evidence is fragmented across disparate systems, and brittle correlation logic fails when activity spans domains or involves novel sequences. The critical missing requirement is a continuously usable model of Organizational Context, a living graph that links identities, assets, and business criticality in real-time. Adopting a Hybrid Analytics operating model with a mature context layer is essential to shift the SOC’s focus from event reconstruction to automated validation and response judgment.
The path forward requires transforming isolated alerts into evidence-supported cases via agentic, cross-domain investigation. This evolution must lead to a staged model of Autonomous Containment, where low-blast-radius actions are automated within stable, auditable guardrails. Artemis Security is examined as a practical implementation of the model: an AI-native SecOps decision runtime designed to connect environmental context, adaptive detection, investigation, and scalable autonomous response. The core objective is to reduce the attacker’s window of opportunity by prioritizing the inspection and reversibility of actions, thereby significantly reducing time-to-decision and time-to-containment.
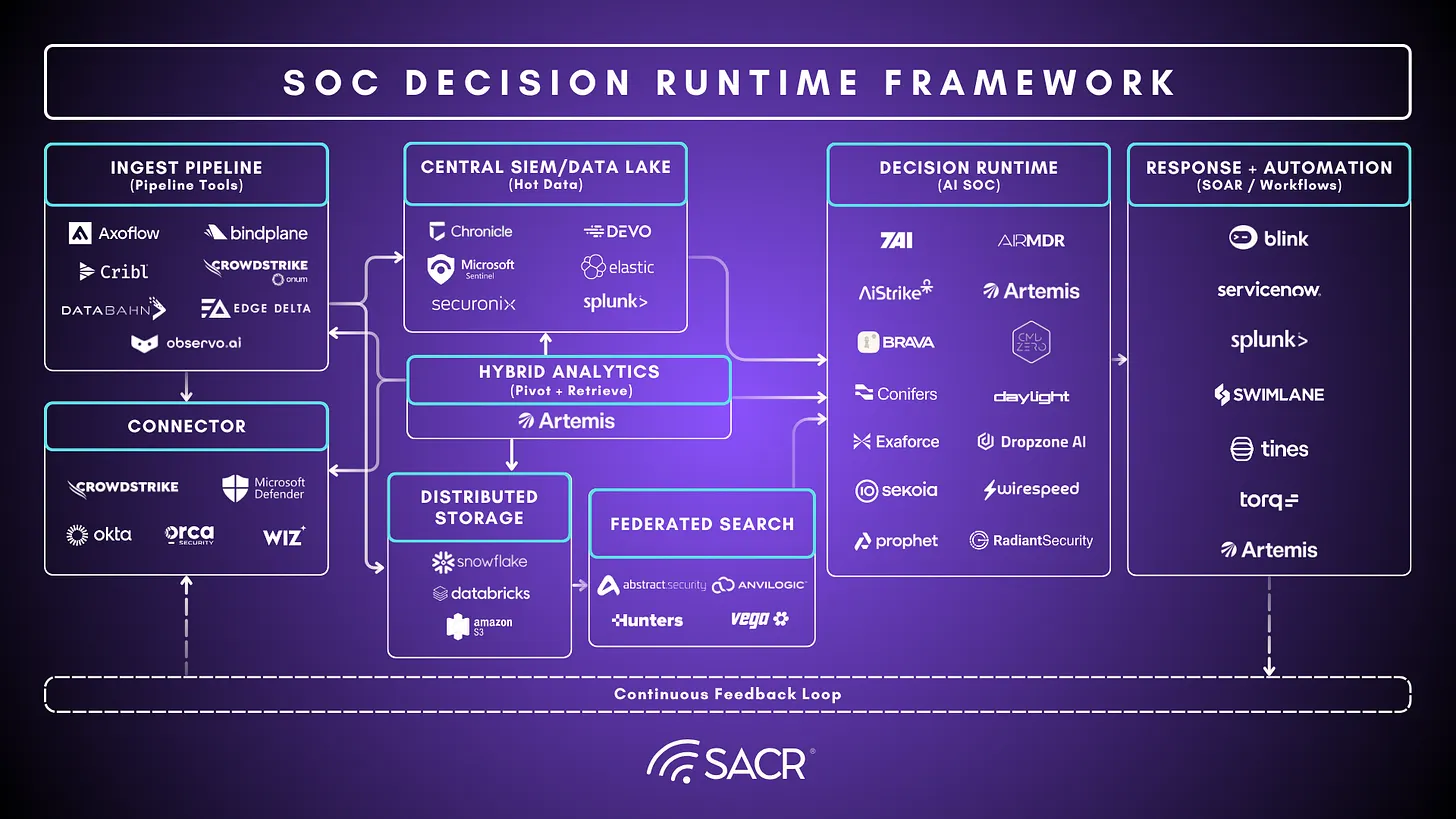
Defining the Problem: Defenders Operate Too Slowly
Security operations centers increasingly treat detections as hypotheses that must become response actions. The timing problem remains the central constraint. Attackers benefit from automation, repeatable tradecraft, and AI-assisted workflows that compress the interval between initial access and material impact. Defenders still carry approvals, handoffs, and human review on the critical path. The result is a mismatch in operational tempo with attackers moving at machine speed while the SOC assembles context at human speed.
Threat Detection faces the same compression problem. From an adversarial perspective, Mythos and other related models accelerate the interval between attacker intent, technique selection, execution, and adaptation. Security programs built around static rules, periodic content reviews, manual tuning, ticket-based investigation, and delayed context enrichment struggle in this environment because attackers can vary behavior faster than defenders can validate, tune, and operationalize new detection logic. Vulnerability management addresses exposure before exploitation. Threat detection addresses the live operating window once activity begins, when weak signals must become validated cases quickly enough to support containment. The practical requirement is AI-augmented detection and investigation that can reason over local context, test hypotheses against current telemetry, generate or adjust detection logic, and convert emerging activity into reviewable cases before the response window closes.
The practical bottleneck is the effort required to turn scattered signals into an actionable storyline. A case is the operational container; the storyline is the time-ordered, context-enriched explanation of behavior inside it. That storyline supports containment, escalation, or further investigation. Analysts still spend large amounts of time retrieving evidence, reconciling naming differences, and deciding whether separate events belong to one chain of activity. Cross-team communication adds more latency when ownership, business criticality, or dependency information sits outside security tooling. The SOC therefore becomes a manual context assembly line.

Detection is rarely the slow stage. Modern tools can produce alerts immediately, yet the step from signal to response action still depends on local judgment about who is involved, what systems are affected, and how much business risk is attached to the proposed response. Generic detections intensify that burden because they carry limited organizational context. Each alert becomes a local reconstruction project. Response speed is therefore tightly coupled to context quality. When containment depends on repeated lookups, each candidate case waits until someone can estimate impact and blast radius with enough confidence to act. Alert volume compounds that queue. Noise consumes triage time, triage creates backlog, and backlog extends the window in which an attacker can move before containment.
Why Current Architecture Breaks
Many detection architectures are optimized to surface signals and only partially support response actions. They can identify suspicious events and group them into incidents, yet they often leave the storyline to the analyst. The core operational questions remain open: what happened, why it matters in this environment, and what action is justified now. When risk, asset criticality, and ownership are absent from the signal, triage teams rebuild that picture case by case.
Fragmentation makes that problem worse. Enterprise investigations routinely require movement across SIEM, SOAR, endpoint, identity, cloud, and SaaS security consoles. Each console may have its own object model, severity logic, retention policy, and workflow assumptions. Analysts, therefore, spend critical minutes translating between tools, checking whether identifiers refer to the same entity, and manually carrying facts from one interface into another. Multi-vendor environments can produce strong local detections while still creating a slow global investigation.
This fragmentation increases handoffs, lookup time, and uncertainty. Evidence relevant to one incident may sit across major telemetry systems and various operational records. Cross-domain investigations are routine, yet many architectures still assume that correlation will happen through narrow identifiers or static rules. That approach degrades when activity spans domains, when attackers vary a familiar sequence, or when the analyst needs to connect technical events to organizational consequences. Correlation itself is often brittle and shallow. Rules work well for known patterns with stable fields, yet they capture novelty poorly and rarely express the full behavioral chain that matters in an investigation. Pipeline complexity adds further fragility. Schema drift, parser failures, ingestion gaps, and broken joins can quietly erode the evidentiary path while dashboards still show detections as deployed. The result is uncertainty disguised as coverage.

Cost and latency pressures deepen the architectural tradeoff. Full centralization improves query convenience, though cost rises quickly at telemetry scale. Pure federation reduces some storage pressure, though it adds latency when investigators need immediate answers. Analysts then escalate disruptive decisions with incomplete context about blast radius, asset importance, or likely business effect. Volume overwhelms investigation capacity, and engineering effort is absorbed by false-positive management while investigative capability grows more slowly than the attack surface.
The Missing Requirement: Organizational Context
The missing requirement is a continuously usable model of organizational context. Security decisions depend on understanding the relationships among identities, assets, permissions, ownership, criticality, and related dependencies. In practice, this means a living context graph that becomes the central architectural object for investigation and response. Current security frameworks increasingly formalize this requirement by treating inventories, entitlements, operational flows, and mission impact as part of the detection and response foundation. Without that layer, an alert remains an isolated technical artifact with limited operational meaning.

The graph changes the quality of judgment because it supplies the decision dependencies required to interpret behavior locally. It helps determine whether a suspicious login belongs to a privileged account, whether the accessed system sits on a production path, whether the target workload supports downstream services, and whether containment would interrupt a critical business function. These relationships allow teams to estimate operational risk with precision. They also matter because modern incidents frequently cross organizational boundaries, which raises the value of understanding supplier dependencies, delegated access, and exposure paths before acting.
The graph must span domains and stay fresh. Modern attack paths commonly move through identity, endpoint, cloud, and application layers within the same chain of activity. A useful investigative model connects entities and events across those layers in near real time and stays synchronized with identity providers, cloud resource managers, configuration systems, and related authoritative sources. Freshness matters because impact estimation depends on current relationships. A stale dependency graph can create false confidence and distort containment choices.
At the implementation level, the living graph should be populated from existing telemetry, configuration, identity, and related pipeline tooling. It should also be exposed to agents through a controlled interface, including MCP-compatible access where appropriate, so investigative agents can query current context without hard-coding knowledge of every source system. The graph then becomes a shared decision surface: tools feed it, agents reason over it, and cases inherit current business context from it.
A mature, living graph and context layer changes how investigations are assembled. Software agents can query the graph and underlying sources directly to validate alerts, collect supporting evidence, and surface the small set of facts that drive a response action. Analysts then spend less time retrieving data and more time judging scope, business impact, and response options. The operational product is a context-enriched storyline that can be inspected, challenged, and acted on.
Hybrid Analytics as the Operating Model

A workable operating model balances speed, depth, and cost. The most time-sensitive detections and decision inputs need low-latency access close to the analytic engine, while lower-frequency or historical evidence can remain in remote systems that are queried when deeper context is required. This is a hybrid analytics model: keep hot-path data close to the decision point and reach back selectively for depth. The hot-path is the data, context, and derived state needed inside the response decision window.
This approach treats data placement as an operational design choice. Common decision inputs should be pre-positioned for rapid access: current identity state, asset criticality, entitlement context, recent high-value telemetry, and relevant graph relationships. Long-tail history and specialized evidence can remain federated until a case justifies the additional cost or latency. Cheap sensing can surface candidates broadly, and targeted retrieval can add depth where it improves the response action.
The operating sequence is straightforward. First, the platform keeps the hot path current through normalization, enrichment, and continuous graph refresh. Second, detections promote candidate cases into storyline assembly when they meet policy or confidence thresholds. Third, agents query the graph and selected source systems to fill evidence gaps, test alternative explanations, and identify the likely blast radius. Fourth, the resulting case presents a response recommendation with supporting evidence, uncertainty, and expected business effect.
Hybrid analytics also creates a stronger foundation for continuous baselining and case assembly. When the critical context required for common investigations is already positioned for rapid access, analysts and automated agents can evaluate meaning faster. Agents perform targeted retrieval from deeper sources; analysts spend less time manually gathering evidence and more time reviewing judgment, scope, and action eligibility. The architecture is then tuned around time-to-decision as a measurable operating metric.
This design depends on continuous coverage validation. Selective architectures fail quickly when required fields, pivots, or joins drift out of availability. Teams should measure whether hot-path inputs remain fresh, whether federated retrieval meets case latency targets, and whether missing context delays containment. Hybrid analytics succeeds when the system can assemble a decision-grade storyline inside the operational window available for response.
Evolution from Alerts to Agentic Storyline Assembly
The operational unit of value in modern security is the case, which transforms isolated alerts into explicit hypotheses supported by assembled evidence and impact framing. A strong case must consistently answer what happened, why it matters, and what to do next, shifting incident response from simple detection to the reconstruction of events, storyline of sequences and scope. This transition ensures that analysts act on complete narratives rather than fragmented technical signals.

Examples of Events, Incidents vs Storyline:

Incident:
SOC Incident (Traditional View)

Cross-domain assembly is central to that shift. A meaningful storyline often has to connect identity, endpoint, cloud, and network evidence into one behavioral chain. That assembly should happen through agentic evidence-gathering that queries the context graph and source systems directly. Agents can validate the initial signal, collect the pivots that shaped the case, and turn isolated events into an inspectable explanation. Human effort is then concentrated on validation, trade-offs, and final judgment.
Incident Storyline
LLM Summation With Business [Context Elements] Retrieved In Realtime
The system’s [operational maintenance] protocols were triggered by the [service-level scheduling] engine, ensuring [business continuity] by automatically executing critical background health checks. This seamless background process maintains the [infrastructure reliability] necessary to support [high-stakes research output] and [project-critical performance] for your professional operations.
Context Source Elements (Business Context Examples)
Context Mapping in the Enterprise SOC

A compact example illustrates the difference. A raw event may show an impossible-travel login for a privileged user. A traditional incident may add related events such as a new token, unusual cloud console activity, and access to a sensitive workload. A storyline adds local context: the user owns a production service, the accessed workload supports a revenue process, the activity occurred outside the user’s normal pattern, and containment would affect a defined dependency path. The response discussion can then focus on scoped actions, such as token invalidation, step-up verification, or temporary privilege reduction.
This is why the case contract matters. A useful storyline needs a time-ordered evidence trail, the key pivots that shaped the narrative, scope indicators, and a confidence statement that makes assumptions and gaps visible. When a system recommends action, it should also produce a replayable artifact that records what evidence was pulled, what context sources were consulted, and what policy thresholds were applied. Inspectability makes faster responses governable.
A subset of candidates deserves this level of work. The system should promote the signals that justify deeper investigation, because the purpose of the model is to concentrate scarce analyst attention where it changes the outcome. Transparent confidence scoring supports that prioritization and reduces unsupported precision. Decision quality improves when uncertainty is explicit, and review effort begins from a standardized evidence bundle.
The Practical Path to Autonomous Containment
Faster investigation matters when it produces faster, safer response actions. Real-time defense remains difficult when every action depends on manual lookup, informal coordination, and high-latency approval. The practical path forward extends from agentic storyline assembly into guided response, then selective automation. The early objective is to reduce avoidable delay for actions that are reversible, well-scoped, and defensible under policy.
This suggests a staged model. First, the system assembles the storyline, estimates business impact, and prepares a recommended response while a human remains in the approval loop. Next, organizations automate low-blast-radius steps such as session revocation, token invalidation, or isolation of non-critical assets when the context graph shows that business risk is limited. Broader autonomy becomes practical when guardrails are tied to asset criticality, dependency awareness, recovery paths, and scoped permissions.

The storyline becomes the control surface for governed action. It should show the behavioral chain, affected entities, confidence level, operational impact, and policy basis for the recommended response. That structure allows the organization to classify action risk clearly and decide which steps can be executed automatically, require approval, or need business-owner review.
The core requirement is trust grounded in inspectability. Teams rely on automated containment when they can reconstruct why a decision was made, what evidence was considered, what context sources were consulted, what threshold justified the action, and how the action can be reversed. The operational prize is meaningful because shorter time-to-decision and time-to-containment reduce the opportunity window available to the attacker. Autonomous response becomes viable when the system combines speed with bounded operational risk.
The control model matters as much as the detection model. Changes to thresholds, suppressions, routing logic, and automation eligibility should be treated as production changes that are reviewable, testable, and reversible. Approval gates, policy constraints, explicit eligibility rules, and prevalidated recovery procedures make autonomous action operationally credible.
The Artemis Platform
Profile Summary
Artemis Security is an AI-native security operations platform designed to compress the interval between detection, investigation, and response. It fits this report as a practical implementation of the operating model described earlier: a living context graph, hybrid analytics, agentic storyline assembly, and governed response.
The platform builds a continuously updated model of the customer environment, uses that model to generate and tune detections against local telemetry, and applies agents to investigate alerts across connected sources. Its intended output is autonomous protection that is built by a decision-grade case that explains what happened, why it matters in the local environment, which evidence supports the conclusion, what remains uncertain, and which response options are appropriate.
The earlier Artemis profile from The Future of Detection Engineering in Security Operations treated the company primarily as an upstream detection and context engine. That framing remains useful, and the stronger report fit is now broader. Artemis is positioned around the full loop from adaptive detection to evidence-backed investigation, response-ready case assembly, and automated response. The core objective is faster, governable containment, with detection quality serving that outcome.
Market Context
Artemis reflects a broader shift in SecOps from alert production toward decision-grade case output. Detection-as-code improved rule discipline, and many teams still struggle with rule drift, uneven telemetry, and manual interpretation. Artemis addresses that maintenance burden by using AI agents and a structured environment model to generate customer-specific detections, investigate activity across connected sources, suggest the right action to take for the case created, and help the customer take it with the click of a button.
For this report’s taxonomy, Artemis is a candidate for the decision-runtime layer of the stack. It overlaps with AI SOC tools, next-generation SIEM initiatives, detection engineering acceleration, and investigation automation. Its differentiation is the attempt to make customer-specific detection, investigation, and response loops reliable at scale without pushing hidden operational work back onto the SOC.
Product Architecture & Workflow
Artemis begins with environmental intelligence. The platform builds a living model of users, AI agents, assets, access relationships, normal behavior, and business context. It allows the system to evaluate a login, cloud API call, endpoint event, or SaaS action against who the actor is, what they normally do, what they can access, and which assets matter.
That context layer supports adaptive detection engineering. Artemis can take threat intelligence, analyst intent, or hunting questions as inputs, map relevant behaviors to the customer’s telemetry, and generate detections tuned to local structure and risk. Natural-language detection building and threat hunting reduce dependence on specialized query languages for common workflows. The underlying system still includes the disciplines of detection-as-code: versioning, review, testing, deployment gates, and rollback.
The platform also fits the hybrid analytics model. Artemis can connect to log sources directly and also query security data where it lives, whether it’s existing security systems like EDR, data stores like S3, or data warehouses. Common decision context stays close to the case workflow, and deeper evidence is retrieved when a case justifies the cost or latency. This matters in environments where evidence sits across SIEMs, cloud logs, identity systems, endpoint telemetry, and various SaaS sources.
When a detection fires, Artemis agents form hypotheses, query relevant sources, correlate signals, including alerts created by other security vendors, and produce a structured report with storyline, evidence, severity assessment, and response options. Identity, cloud, and endpoint sources are useful examples because they show how source-specific expertise can be encoded into the investigation. The product’s credibility depends on whether the output remains auditable, with evidence and reasoning visible enough for analyst review.
The response layer is the governance test. Artemis can become more valuable as it moves closer to containment. That proximity raises the requirement for policy boundaries, blast-radius awareness, approval paths, and rollback mechanics before recommendations can support execution. Autonomous action becomes credible when the case record shows the evidence used, the context consulted, the threshold applied, and the recovery path available.
Strategic Strengths
Artemis’ primary strategic strength is the integration of adaptive detection with environmental modeling. Many AI SOC products begin after an alert already exists. Artemis moves upstream to influence the quality of the signal before it reaches the analyst, then carries that context forward into investigation and response.
A second strength is alignment with hybrid data economics. Enterprises increasingly spread security data across different cost and latency tiers. Artemis’ retrieval model gives it a way to preserve investigative depth and control ingest cost, especially in environments with evidence distributed across cloud, identity, endpoint, and SaaS systems.
A third strength is the consistency of the product narrative. Artemis has a clear answer to why AI matters in SecOps: AI is useful when it reasons over a structured model of the environment and produces reviewable cases. That framing is stronger than generic copilot positioning because it ties AI capability to a concrete architectural dependency.
Reported customer outcomes support the thesis, including higher detection coverage, environment-specific intelligence within 24 hours, and substantial reductions in mean time to resolution. These claims should be treated as deployment-specific evidence. The right validation questions are baseline process, alert mix, response scope, degree of automation, and how much work was included in the measurement.
Trust and Validation Checkpoints
Artemis raises the right buyer questions because it asks AI to reason over sensitive evidence and propose action. Cases and detections need clear provenance: cited evidence, visible assumptions, uncertainty, and an audit trail that analysts can inspect. Confidence scores are useful only when paired with the evidence path that produced them.
Coverage health is equally important. Adaptive systems need to distinguish low activity from missing visibility. If telemetry gaps, schema drift, or broken integrations are interpreted as a clean environment, the platform can create silent coverage failure. Artemis needs to surface the health of the evidence plane as clearly as it surfaces the case output.
Data handling also matters because the platform operates on sensitive security evidence. Dedicated environments, tenant separation, and model-training exclusions are material procurement details that should be verified directly. These controls become more important as the system moves from investigation assistance toward response recommendations.
Competitive Positioning
Artemis competes across several adjacent categories: AI SOC, next-generation SIEM, detection engineering automation, investigation automation, and response orchestration. Its strongest position is the full loop from context to detection generation, investigation, and response-ready case assembly. If that loop performs consistently, Artemis functions as a context-driven decision runtime for SecOps.
The main competitive risk is fragmentation of the value proposition. If the living environment model drifts, the platform can collapse into point capabilities such as rule generation, chat-based hunting, and narrative summarization. The central test is whether Artemis can make every stage of the workflow more reliable because each stage inherits the same current model of organizational context.
Bottom Line
Artemis is best read as a bet that decision-grade cases are becoming the new output format of the SOC. Detections and investigations become more valuable when they inherit a continuously updated model of the customer environment. The strategic question is whether Artemis can preserve trust through governance, provenance, and bounded autonomy as it compresses the path from signal to response.
Practitioner Takeaways
Practitioners should treat the case as the unit of SecOps modernization. The highest-value measurement is whether the organization can move from signal to decision with enough evidence, context, and confidence to justify action. Time-to-decision and time-to-containment should sit beside conventional alert metrics because they show whether detection output is becoming operational judgment.
The context layer should be managed as production infrastructure. A living graph only helps when it stays current, so identity state, asset criticality, entitlements, ownership, dependency paths, and recent high-value telemetry need active refresh, monitoring, and testing. The same discipline should apply to the hot path. Common decision inputs should remain close to the case workflow, while deeper evidence can be retrieved when the case justifies added cost or latency. In practical terms, data placement becomes an operating choice tied directly to response speed.
Storylines also need to be inspectable enough to support action. Each case should show the behavioral chain, supporting evidence, key pivots, assumptions, uncertainty, and response rationale. That structure gives analysts a reviewable artifact they can challenge, approve, or use for containment. It also creates the foundation for selective autonomy because automated action becomes more credible when the organization can reconstruct why a recommendation was made and what recovery path is available.
Autonomy should begin with reversible actions and a narrow blast radius. Early automation should focus on bounded steps such as session revocation, token invalidation, and temporary privilege reduction. Higher-impact actions require explicit eligibility rules, approval paths, and rollback procedures. For buyers, the validation focus should therefore extend beyond feature coverage to evidence provenance, graph freshness, coverage health, tenant controls, action auditability, and recovery mechanics. The core question is whether Artemis improves decision quality while reducing response latency.
Conclusion
The SOC’s tempo problem is ultimately a context problem. Security teams can detect suspicious activity faster than they can assemble the local facts required to decide what action is justified. A living context graph, hybrid analytics model, and agentic storyline assembly give that decision process a stronger architectural base by linking evidence to identities, assets, dependencies, and business impact.
The strategic shift is from alert production to decision-grade case assembly. The case becomes the place where detection, investigation, business context, and response governance converge. When that case is supported by the current organizational context and a replayable evidence trail, analysts can spend less time rebuilding what happened and more time judging scope, impact, and action eligibility.
The practical direction for SecOps is clear: build systems that make judgment faster while keeping reasoning visible. Decision-grade cases should become the common output of detection, investigation, and response. The organizations that get there first will reduce avoidable latency during incidents and act within clear, auditable guardrails.