Executive Summary
Security operations teams are not failing because they lack detections. They are failing because alert-centric models cannot convert weak, high-volume signals into consistent decisions at operational scale. The SOC becomes a context assembly line, and coverage becomes inventory rather than outcomes.
Content libraries and technique coverage are not durable differentiators unless the platform can keep coverage real in production and consistently promote signals into decision-grade cases. The market is moving beyond static rules and beyond detection-as-code toward a case-first, decision-runtime model. In this model, the output is an investigation-ready case with an explicit hypothesis, bounded evidence, and environment specific context, not an alert that demands manual reconstruction. That output contract is the forcing function for the next wave of detection engineering. It requires platforms to separate sensing from deciding, retrieving decision dependencies on demand, and preventing silent failure as telemetry and schemas drift.
In this report, we define what a detection is and how detection engineering works today, map how the market has evolved, define the capabilities required to run detection as a decision runtime, and analyze a select list of vendors to show how the market is converging on case-first workflows in practice.
Successful security leaders should evaluate detection programs and platforms on decision outcomes, not signaling volume. In practice, that means measuring time-to-decision and outcome consistency instead of alert counts or ATT&CK mapping. Explicitly prioritize coverage integrity by identifying ingest gaps, and schema drift so detection logic does not silently fail in production. As AI assistance increases, leaders should require provenance for triage, reasoning, and tuning recommendations, and adopt autonomy in tiered stages that bind write actions to specific permission and approval gates.
In practice, winners will be the platforms that can run this loop reliably in production with measurable coverage, bounded decisions, and tuning that improves outcomes without creating silent failure or un-auditable autonomy.
Throughout the report, we performed an analysis of four key vendors across this ecosystem.
Cribl which started as a telemetry pipeline company has extended out to incorporating search and federation as the control plane that can allow companies to query data across S3/Azure Blob and other sources/APIs without needing to pre-normalize everything daily. They can ingest directly into Search (Stream optional).
Panther’s future-of-detections story is “agentic SOC closure” that covers the gap from triage dispositions feed detection tuning to reduce alert volume.
Vega’s acts as a federated detection fabric with adding detection rule health. The core premise of their solution is to ensure a client has continuous coverage/quality across distributed data. In addition, we need to have AI reducing evidence retrieval and drift-induced breakage.
Artemis emphasizes applying detections to the customer’s real fields/assets/sources and continuously measuring whether they work.
First Principles: Defining Detections and Why It Breaks at Scale
Detections within SecOps are logic rules that identify potentially malicious or suspicious behavior from telemetry log sources. They generate a signal that requires validation. It is essentially a decision-support mechanism that turns raw security telemetry into an hypothesis about adversary behavior. It is not a verdict and it is not an outcome. They are typically implemented as a query, rule or model to detect behaviours that go beyond normal.
A detection asserts, “This activity may matter,” and it does so with enough structure that a security team can validate the hypothesis, understand what it implies, and decide what to do next. In practice, detections are expressed as logic over observables and behaviors, and they only create value when they reliably translate machine-scale activity into human- and system-actionable work.
This definition matters because “detection” is often conflated with adjacent disciplines. Detections are not vulnerability findings, compliance gaps, or posture issues, which describe risk conditions that can exist without any active adversary behavior. Detections are also not simply alerts. An alert is a delivery mechanism. A detection is the underlying hypothesis and the evaluation process that produces a signal worth attention. Treating alerts as the unit of success leads to volume, noise, and inconsistent outcomes, because it optimizes for signaling rather than for decisions.
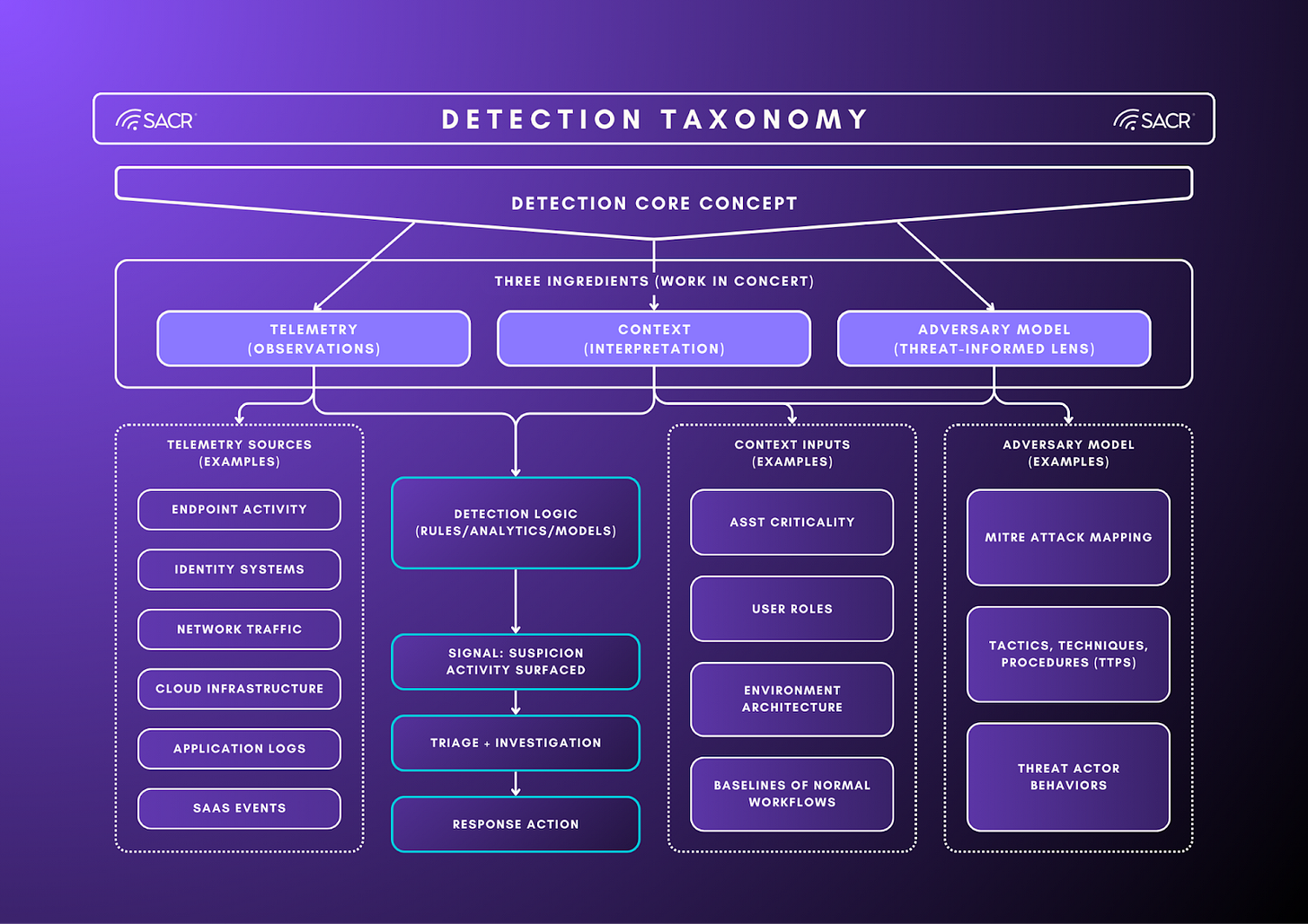
A detection is a function that maps telemetry + context into a prioritized investigative signal. A useful way to evaluate any detection system is to ask what it produces at the end of the chain. A mature detection program does not optimize for “more detections deployed.” It optimizes for decision-grade work units: cases that arrive with sufficient context to answer three questions quickly and consistently. What happened? Why does it matter here? What to do next. When detections fail, they fail because they produce outputs that are under-specified for decision-making or under-justified for the work they create. They identify technique presence without establishing relevance to the environment, they surface anomalies without an investigative path, or they generate signals without enough evidence to route, scope, and respond.
Below is a taxonomy that breaks down the categories. Detections reflects real-world complexity that aggregate telemetry (logs), context (asset, identity, behavior) and threat model (ATT&CK, TTPs).
Current State of Detection Engineering Lifecycle
Detection engineering has developed in recent years as a methodology for how security teams organize and manage their detections. The following are core steps that make up the lifecycle
- Detection Creation
- Detection begins with a threat theory about how an attacker would behave in your environment. Detection engineers translate adversary tradecraft (from new solutions within your enterprise environment, threat intelligence sources, or frameworks like MITRE ATT&CK) into observable behaviors that can be monitored in telemetry.
- The hypothesis is converted into detection logic. Engineers write rules, queries, or analytics that identify suspicious patterns in logs and telemetry. This stage focuses on translating attacker behavior into operational detection logic that can run reliably on available data. These are created on SIEMs or detection platforms using query languages like KQL, SQL or SPL detections depending on the platform.
- Detection Testing
- Before deployment, detections are validated to ensure they trigger on real attack behavior and avoid excessive false positives. Testing typically involves replaying logs, running adversary simulations, or executing red team techniques to confirm that the detection works as expected. The common platforms used are splunk attack range or AttackIQ.
- Detection Deployment
- Once validated, the detection is deployed into production monitoring systems. Detection rules are activated in SIEM or detection platforms and integrated into SOC workflows so they can generate alerts or investigation signals when triggered. These are commonly deployed on SIEM detection platforms like Splunk, Google SecOps or CI/CD pipelines or Detection-as-code platforms like Panther.
- Detection tuning
- After deployment, detections are continuously refined to improve accuracy and reduce operational noise. Engineers adjust thresholds, add contextual filters, and incorporate environment-specific knowledge to ensure detections produce meaningful alerts rather than unnecessary workload. The common platforms leveraged include SIEM analytics dashboards.
Improving Detection Effectiveness Across Development, Testing, and Tuning
Across the development, testing, and tuning phases, security teams should shift from writing isolated detection logic to operating a feedback-driven detection system grounded in real-world behavior and outcomes. In development, teams can improve by anchoring detections in clear threat hypotheses and ensuring they are built on reliable, well-understood telemetry with explicit assumptions about data quality and context. During testing, teams should go beyond basic validation and incorporate adversary simulation, historical replay, and edge-case scenarios to understand both detection coverage and failure modes, ensuring detections behave predictably under real conditions. In tuning, the focus should be on continuous improvement through structured feedback loops ie. by tracking false positives, missed detections, and investigation outcomes to iteratively refine logic, thresholds, and contextual filters. Across all three phases, the key improvement is to treat detections not as static rules, but as evolving systems that are continuously validated against reality, with success measured by signal quality and decision impact rather than volume.
Operationalizing for the future
Every detection allocates human attention. Whether the platform emits an alert or a case, it is creating an operational work unit that someone must review, route, and close. That means detections should be judged less by whether they are mapped correctly in isolation and more by whether they produce decision-grade work. Outputs that are worth the work arrive to the analyst with enough evidence and context to reach a conclusion quickly and consistently. At scale, the limiting resource is not telemetry volume. It is skilled adjudication. That is why detection performance depends on more than authoring logic. It depends on the system’s ability to reliably combine an evidence plane, decision dependencies, and threat-informed hypotheses into a repeatable decision workflow.
Under this framing, decision-grade does not only mean enriched or context-aware. It means the work item is worth the work it creates. A next-generation detection platform should therefore be evaluated on its ability to promote only the subset of alerts that justify deeper investigation, and to emit cases whose evidence and narrative compress time-to-decision rather than creating new manual assembly steps.
The Three Ingredients of a Decision-Grade Detection
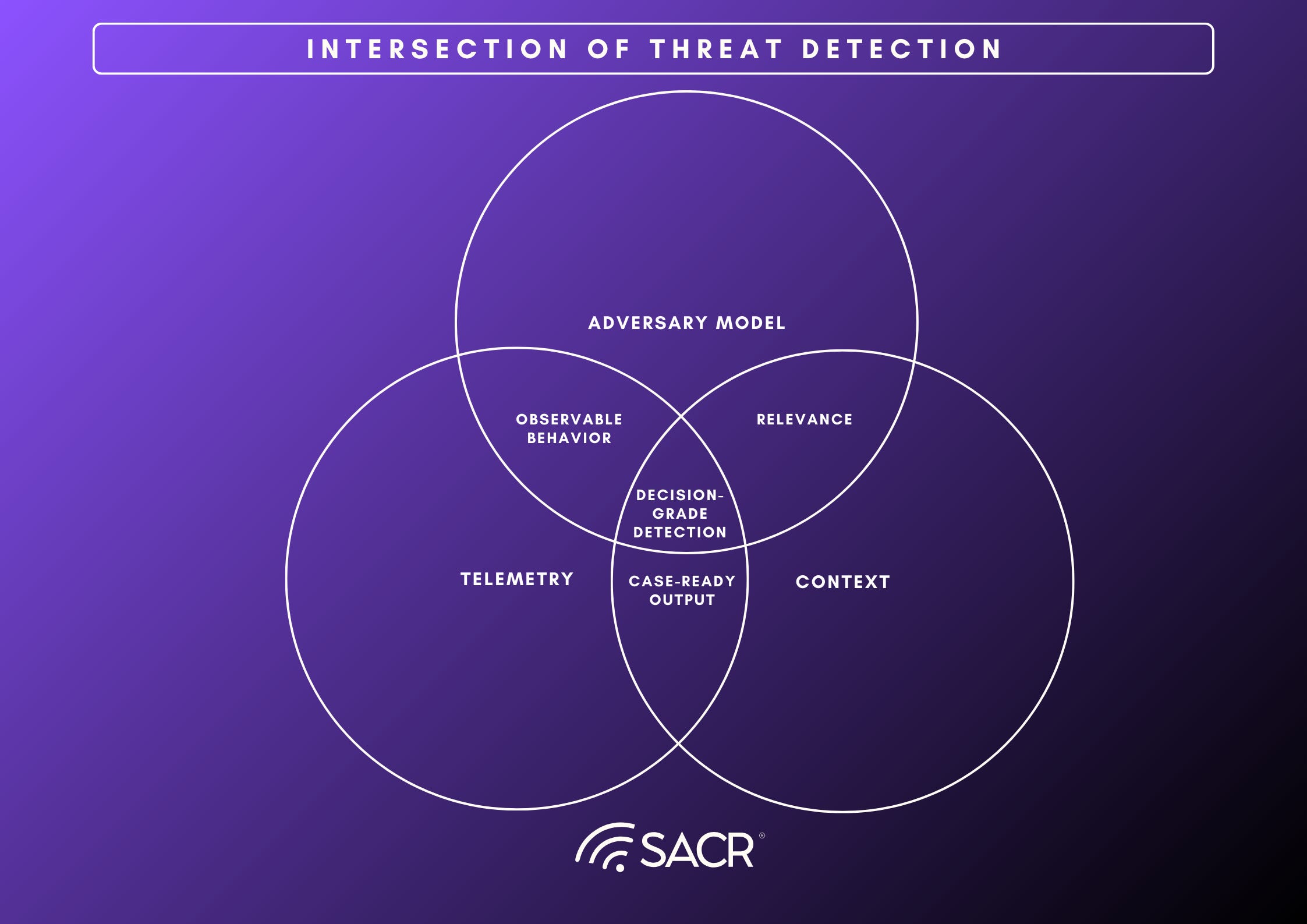
Detections only become operationally useful when they consistently support decisions. That requires three ingredients working together: an evidence plane that reliably captures behavior, decision dependencies that make that behavior interpretable in this environment, and hypothesis scaffolding that frames what “suspicious” should mean and what outcomes the SOC should drive.
- Telemetry is the evidence source: Telemetry is not valuable because it is voluminous. It is valuable because it provides attributable, queryable evidence across the surfaces where adversary behavior plays out: endpoint, identity, network, cloud control plane, SaaS, and applications. In a decision-grade detection program, the evidence plane has four practical characteristics: it is broad enough to cover the behaviors the team claims to care about, structured enough to support repeatable analysis, linked enough to resolve entities (for example, mapping a username, device ID, and cloud principal to the same identity or workload), and economical enough to search at the speed and depth investigations require. When the evidence plane is weak, detection quality collapses into guesswork. Teams either cannot see the relevant behavior, cannot correlate and join the right events together, or can only afford shallow searches that miss the surrounding story.
- Context is the set of decision dependencies: Context is the environment-specific information required to interpret the same observable differently depending on where it occurs. These are not “nice-to-have enrichments.” They are the dependencies that determine whether a signal is relevant and what action is appropriate: asset tier and ownership, identity role and privilege posture, expected workflows, trust boundaries, change state, and current incident state. In practice, decision dependencies are what separate technique presence from risk. Without them, detections tend to fire on generic patterns that are operationally ambiguous, forcing analysts to manually reconstruct relevance each time. That is the root cause of inconsistency at scale: two analysts see the same signal and reach different conclusions because the system did not supply the minimum environment facts needed to decide.
- The adversary model is hypothesis scaffolding. An adversary model provides the threat-informed framing that turns “activity” into “a testable hypothesis.” It shapes what behaviors are worth detecting, how those behaviors should be interpreted, and what the investigation should attempt to prove or disprove. In mature programs, this scaffolding is not limited to mapping detections to technique catalogs. It encodes the organization’s threat priorities, expected attacker tradecraft, and the kinds of narratives the SOC must be able to assemble (initial access, privilege escalation, lateral movement, data access, and exfiltration). When hypothesis scaffolding is thin, detections drift toward anomaly signaling that is difficult to validate and difficult to action, producing work that is investigative in name but not decision-oriented in practice.
When these three ingredients are integrated, detection stops being a content problem and becomes an execution capability: the system can sense behavior with sufficient evidence, pull the decision dependencies needed to interpret it, and apply threat-informed hypotheses that guide investigation toward a clear outcome. The practical result is fewer, higher-quality work items and a detection surface that trends toward case-ready outputs rather than isolated alerts.
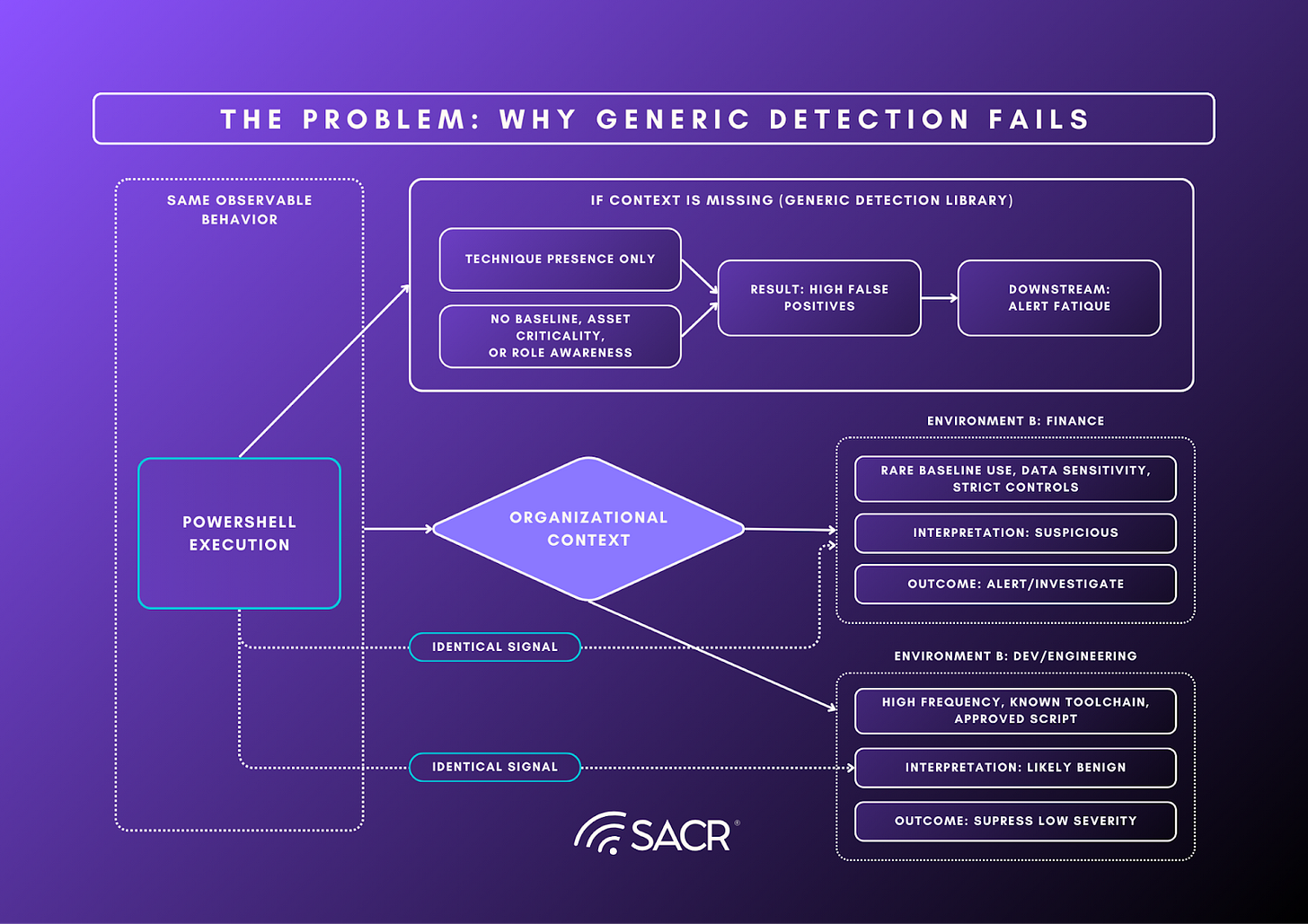
The Context Problem: Why Technique Coverages Fails at Scale
The fundamental constraint on modern detection programs is the context problem: the same observable behavior can be routine in one environment and high-risk in another, and generic detections rarely carry the decision dependencies needed to tell the difference. PowerShell execution, API token creation, or bursts of failed logins are all common adversary techniques, but they are also common in legitimate administration and integration workflows. The signal is not the technique. The signal is the technique in context. When detections are authored against abstract patterns without asset tier, ownership, identity privilege posture, workflow baselines, trust boundaries, and change state, they produce technique-shaped signaling that is under-specified for decisions. The operational result is the SOC becomes a manual context assembly line, and outcomes become inconsistent because gathering context is pushed downstream into human triage.
This is where ATT&CK coverage becomes a trap. ATT&CK is a behavior catalog, not a decision system. Mapping detections to techniques helps inventory intent and communicate breadth, but it does not guarantee that a detection is decision-grade in a specific environment. In practice, ATT&CK-aligned content libraries often optimize for technique presence, which tends to inflate alert volume and tuning debt when the platform cannot reliably supply the context required to discriminate benign from malicious in local workflows. An organization can appear covered on paper while failing operationally.
A more useful framing is to treat ATT&CK as an input to hypothesis selection, not the primary output metric. The question is not “Do we have a detection for Technique X?” It is “When Technique X-shaped activity appears, can we consistently determine whether it matters here?” In a case-first model, progress is measured in time-to-decision, consistency of outcomes, false-positive cost, and the percentage of candidates that can be promoted into high-quality cases backed by explicit decision dependencies.
This is the forcing function behind the decision-runtime model: if the platform cannot retrieve decision dependencies and preserve coverage integrity, technique coverage devolves into workload rather than outcomes
The North Star: From Alerts to Cases
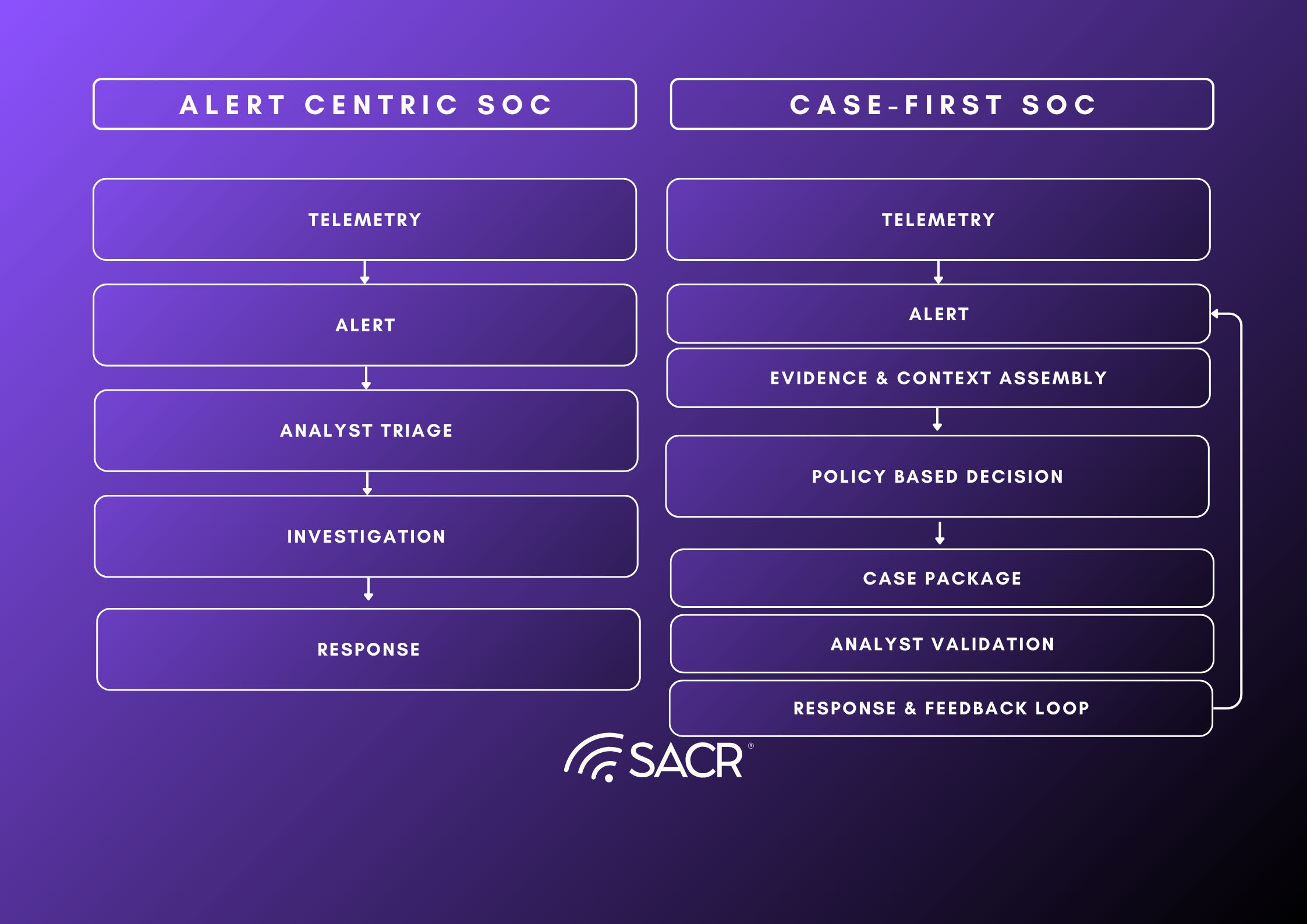
The output of a detection program should not be a growing stream of alerts. It should be a smaller number of decision-ready work units that a security team can validate, route, and resolve consistently. Alerts are a notification primitive. They are useful for surfacing candidate activity, but they are a poor unit of work because they rarely contain the evidence required to make a confident decision. When alerts are treated as the primary product, the SOC becomes an assembly line where human time is spent reconstructing context, stitching timelines, and re-deriving the same conclusions across multiple tools.
A case is a different output contract. A case is an investigation-ready package that makes a hypothesis explicit and provides enough evidence for an analyst to reach a decision with bounded effort. At minimum, a case should answer three questions quickly and repeatably: what happened, why it matters here, and what to do next. In practice, case-quality depends on including a coherent narrative summary, a time-ordered evidence trail with key pivots, the environment-specific context that makes the behavior interpretable, and a confidence statement that makes assumptions and gaps visible. The goal is not to eliminate human judgment. The goal is to move human effort up the stack from “find and assemble” to “validate and direct.”
This shift matters because it reframes the scaling problem in SecOps. The bottleneck is not rule authoring capacity or telemetry volume. The bottleneck is adjudication: converting weak, high-volume signals into decisions that are consistent, reviewable, and operationally actionable. Case-first outputs reduce that bottleneck by standardizing the evidence bundle and the investigative path, so outcomes depend less on individual intuition and more on a repeatable decision process. Over time, the metric of progress changes as well. Instead of tracking success through numbers of detections deployed or techniques mapped, teams can track time-to-decision, false-positive cost, the percentage of signals that can be promoted into high-quality cases, and the rate at which cases close with clear outcomes.
Seen through this lens, alerts to cases is not a UI preference. It is an operating-model shift. The future SOC is defined by its ability to generate decision-grade cases with provenance and governance, at a pace that matches machine-speed attacks and the realities of modern telemetry volume.
The Market Evolution: The Four Phases of Threat Detection
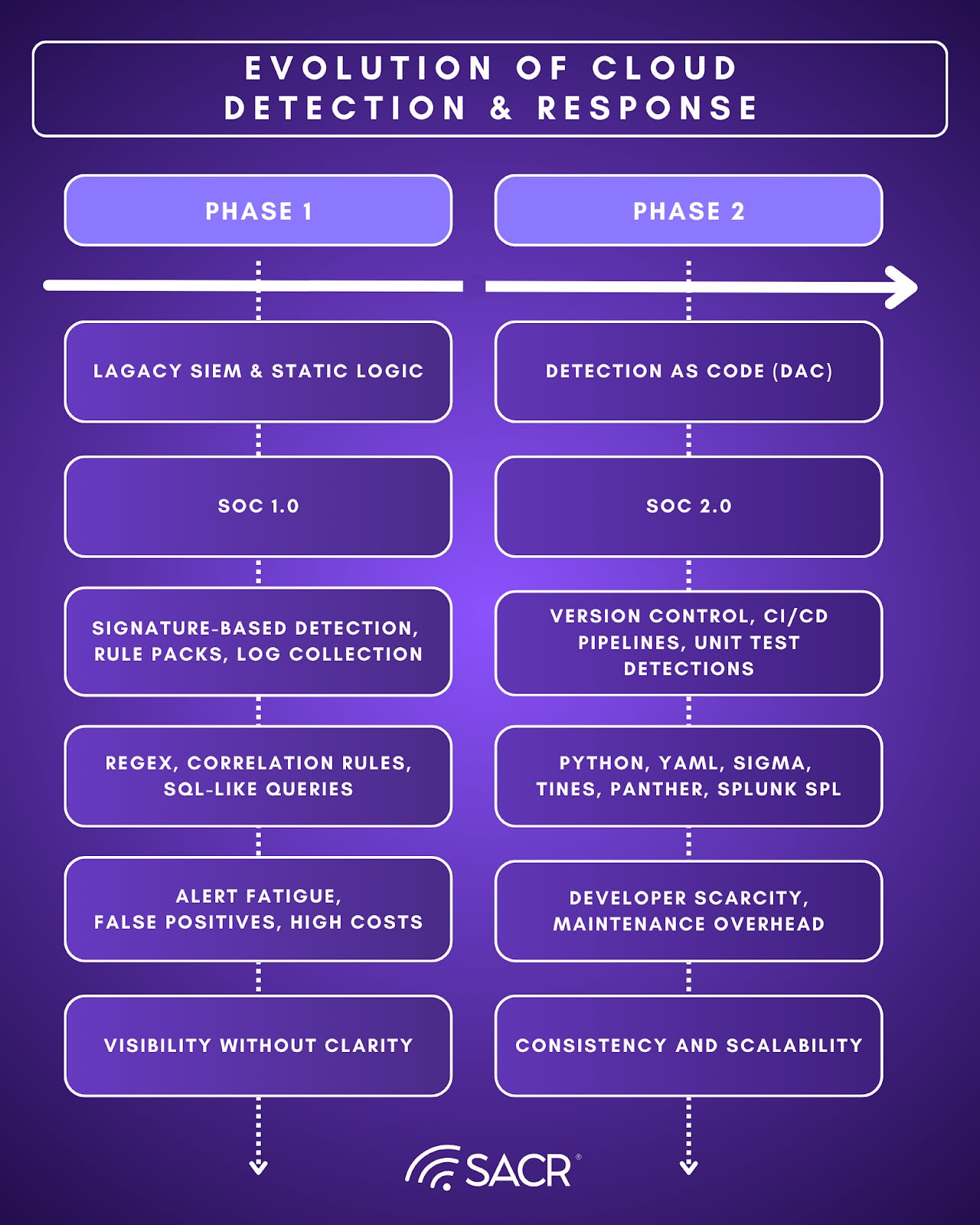
Phase 1: Generic Rules & SIEM Libraries
Phase 1 scaled collection, not adjudication. SIEM rule packs and IOC-heavy detections were broadly deployable, but brittle against dynamic infrastructure and scaled environments. Technique based alerts without context increased detection volume, and the bottleneck became human ability to triage at scale rather than data availability.
Phase 2: Detection as Code
Phase 2 applied software discipline to detections, versioned logic, peer review, and testing. Detection as Code (DaC) improved quality, and speed versus static vendor packs. DaC struggles at scale, portfolios accumulate lifecycle debt as environments, telemetry, and attacker tradecraft drift faster than teams can continuously tune and validate content. DaC improved governance but did not eliminate the human bottleneck in adjudication and maintenance.
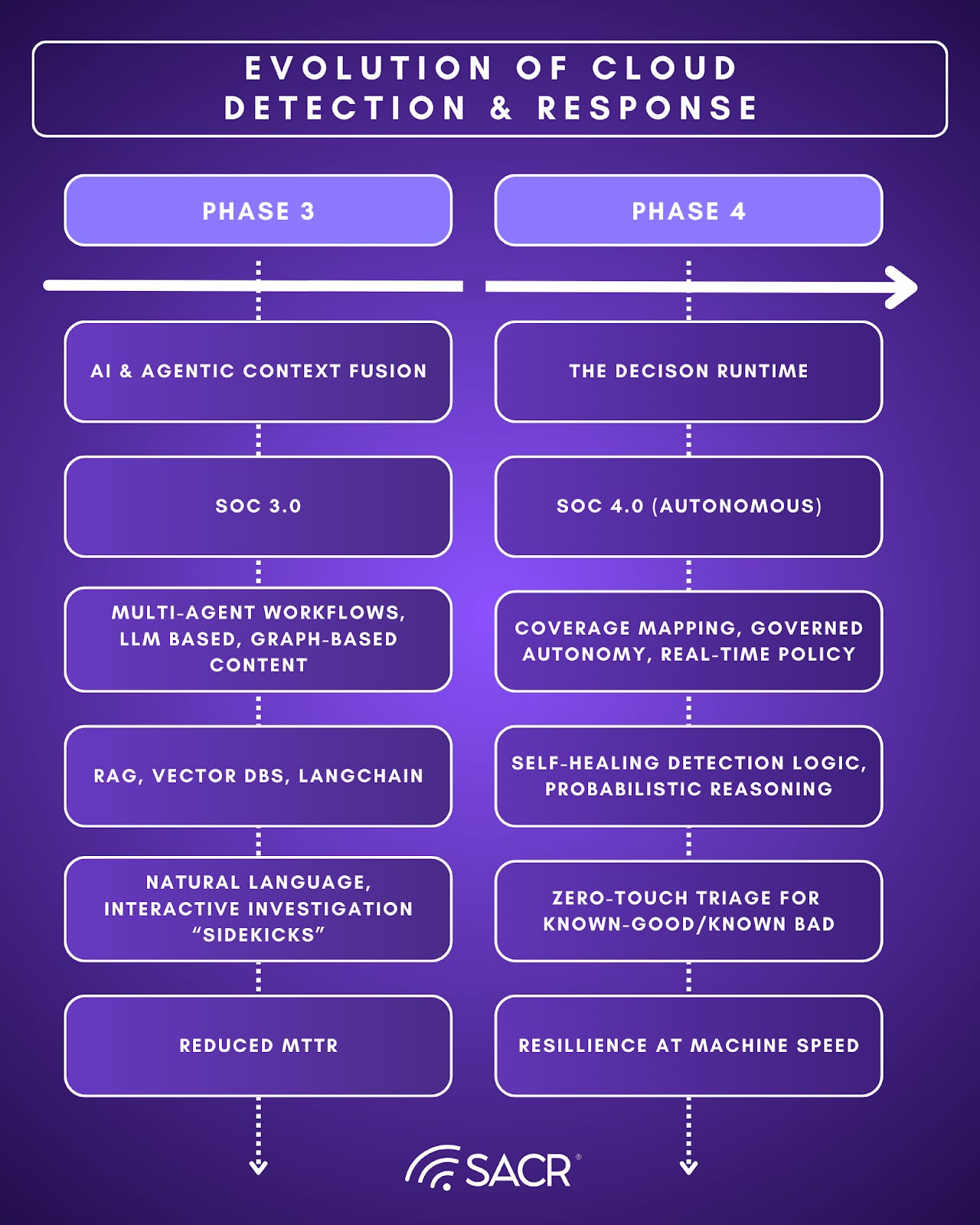
Phase 3: Agentic Detection & Context Fusion
Phase 3 shifts detection from static content toward runtime decisioning supported by context fusion. Agentic systems translate analyst intent into queries and investigative steps, enrich candidates with environment-specific decision dependencies, and draft case narratives that reduce manual assembly. The core risk is not whether the system can generate detections or summaries. It is whether its judgments remain inspectable, reproducible, and governable as closed-loop tuning changes thresholds, suppressions, and routing over time.
Phase 4: The Decision Runtime SOC (Coverage-to-Case + Governed Autonomy)
Phase 4 makes the case-first output contract the organizing principle. The platform senses cheaply to surface candidates, pulls the minimum evidence and decision dependencies on demand, and promotes only the subset that justifies deeper work into investigation-ready cases. This is the shift that drives modern detection tuning and engineering: explicit promotion criteria, measurable coverage integrity, and reliability controls that prevent silent failure as telemetry and schemas drift. Governance becomes inseparable from execution because autonomy can only scale when decisions and changes are auditable, reversible, and policy-bounded.
Core Capabilities of Next Generation Detection Platforms
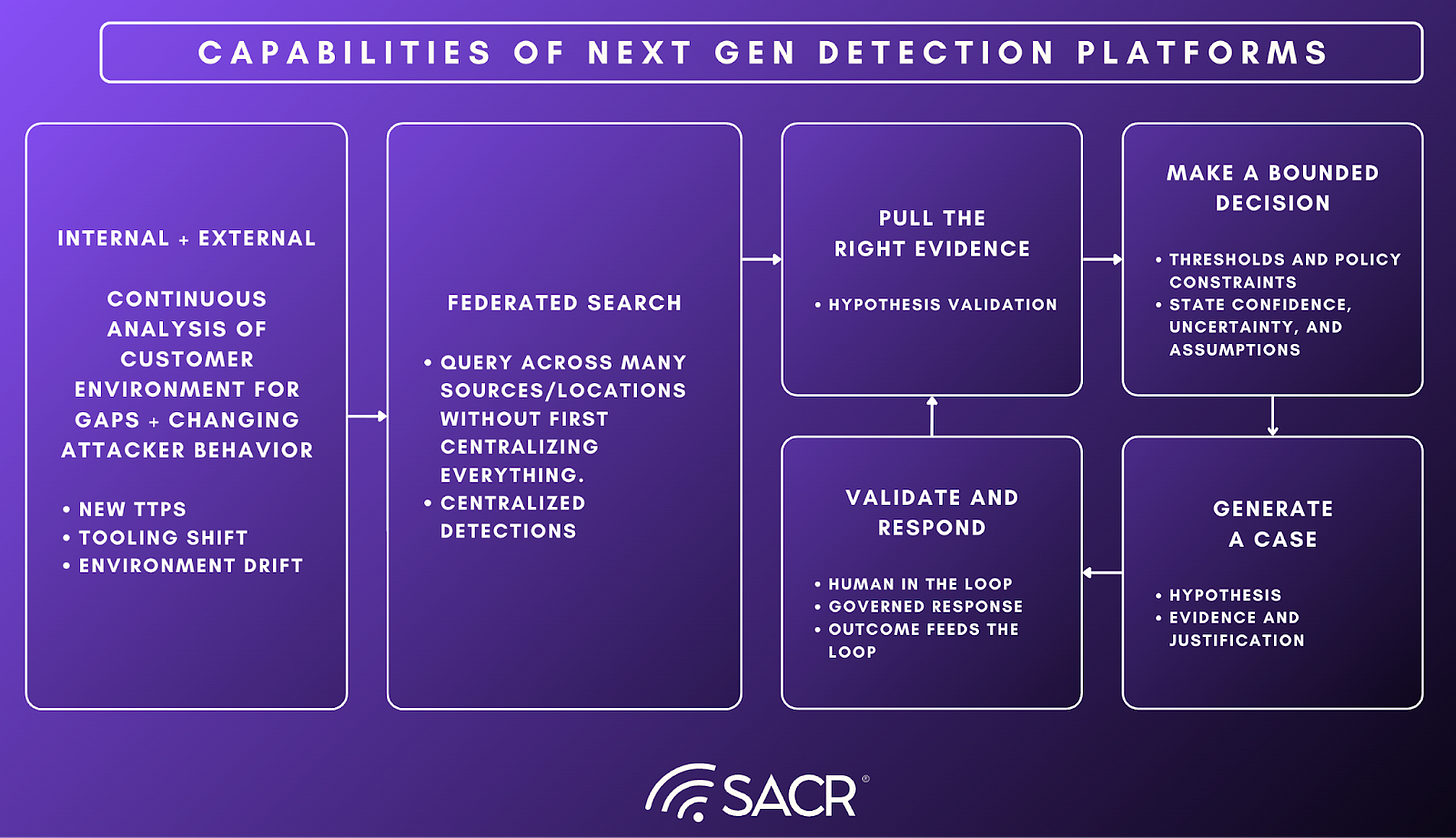
Next-generation detection platforms are increasingly differentiated less by how many detections they ship and more by whether they can convert changing attacker tradecraft into deployable, environment-specific coverage and then into decision-grade cases. In this report, next generation does not mean a new content library or a better correlation engine. It means an operating model where evidence is accessible at the speed of investigation, coverage is measurable and continuously maintained, and case promotion is governed by explicit thresholds, provenance, and auditability. The capabilities below describe what it takes to run detection as a decision runtime: sense cheaply, close coverage gaps quickly, preserve the integrity of detection pipelines as conditions drift, and produce case-first outputs that support consistent triage, response, and continuous improvement.
Foundations: Evidence, Detectability, and Data Economics
Next-generation detection platforms are often discussed as if the differentiator is better analytics or more detection content. In practice, the systems that scale are built on foundations that are more operational than algorithmic: a dependable evidence plane, clear detectability constraints, and a workable cost model. Without those, “case-first” and “governed autonomy” remain interface promises that collapse under real telemetry volume, latency, and drift. The foundational question is simple: can the system retrieve and join the right evidence fast enough to support a decision, and can it do that economically enough that teams will actually use it at scale.
The first foundation is the evidence plane. Decision-grade detections require broad coverage across endpoint, identity, cloud, network, SaaS, and application telemetry, but breadth alone is not the point. What matters is whether the evidence is attributable and joinable in the ways investigations require. That means durable identifiers, reliable entity resolution, schemas that make common pivots repeatable, and normalization that preserves meaning rather than erasing it. When this layer is weak, platforms compensate with heuristics and summaries, but outcomes remain inconsistent because the underlying evidence cannot be queried, replayed, and validated quickly.
The second foundation is detectability: the system must be able to answer what it can actually see, and therefore what it can credibly detect, given the organization’s available logs and attack surface. This is where “coverage” becomes a practical constraint rather than an aspirational mapping exercise. Detection programs drift into false confidence when they claim coverage for behaviors that are not observable in the environment, or when the necessary telemetry exists but is unreliable, incomplete, or inconsistently shaped across sources.
The third foundation is data plane economics: The future SOC cannot assume that every log is ingested, normalized, and retained in the highest-cost tier forever, and it cannot assume that every query can be run indiscriminately without budget consequences. Next-gen platforms treat cost and latency as first-class constraints: tiering, selective retention, federated access, and explicit compute budgets become part of the product, not an afterthought. This matters because both investigation and coverage validation depend on pulling the right evidence when it is needed. If the evidence is inaccessible, too slow, or too expensive to retrieve, the system will revert to shallow decisions and manual reconstruction, and the case-first promise breaks.
Detection Reliability Engineering: Preventing Silent Failure
As detection becomes a runtime, reliability becomes a prerequisite for trust. Detection programs fail not only through false positives and false negatives, but through silent failure: the detection “exists,” but upstream conditions have shifted so it no longer runs correctly. Schema changes, broken parsers, ingestion gaps, field mismatches, index changes, and ETL failures can quietly invalidate coverage while dashboards continue to report that detections are deployed. At scale, this failure mode is more damaging than noise because it produces false confidence.
Next-generation platforms treat detection reliability engineering as a first-class capability. They continuously validate preconditions for detection logic, including whether required fields are present, whether parsing and normalization are functioning, whether data volumes have changed in ways that indicate pipeline breakage, and whether the evidence plane still supports the pivots that investigations depend on. They make “coverage health” measurable and visible, not as a one-time onboarding artifact but as an always-on operational signal.
This capability also changes how teams interpret coverage. Instead of viewing coverage as a static inventory, coverage becomes a maintained system with integrity guarantees and clear failure indicators. When reliability degrades, platforms should surface the blast radius, identify which detection outcomes are compromised, and provide a path to remediation that is governed and reversible. In a decision-runtime SOC, the ability to detect and correct silent failure is not optional. It is what makes higher-level decisioning credible.
Silent failure is not limited to broken ingestion, parsers, or schema drift. As detection becomes more AI-assisted and more runtime-driven, a second class of silent failure emerges on the decision plane: the system continues to run, but its judgments change in ways that are hard to inspect, reproduce, or audit. Closed-loop tuning can quietly shift thresholds and suppressions. AI-generated narratives can appear confident even when key evidence is missing or assumptions are wrong. In a decision-runtime SOC, preventing silent failure must therefore cover both pipeline integrity and decision integrity.
Runtime Execution: Turning Signals into Cases
Runtime execution is where next-generation platforms stop looking like “better detection content” and start behaving like a decision runtime. The job is not to perfectly classify every event. The job is to take weak, high-volume candidates and decide when deeper work is justified, what evidence should be pulled, and how to emit an output that is immediately useful. In this layer, the system earns precision through staged execution: cheap sensing first, selective evidence retrieval next, then adjudication, then case construction. The most important design choice is that sensing and deciding are separated, and that decisions are made with explicit thresholds and traceable inputs.
Runtime execution earns precision through staged work: sensing, selective evidence assembly, adjudication, then case construction. As AI becomes part of adjudication and case construction, the runtime’s output contract must include more than a case summary. It must produce a replayable decision artifact: what evidence was pulled, what context sources were consulted, what policy thresholds were applied, what uncertainty remains, and what model or prompt version produced the reasoning.
The first capability is high-recall sensing. Sensing exists to produce candidates cheaply and consistently, without prematurely paying the cost of heavy joins or deep analytics. This layer favors primitives that scale: lightweight rules, heuristics, baseline deviations, sequence detection, and simple model scores. It should also shape the stream through de-duplication, suppression of known-benign patterns, and entity normalization so downstream work is not overwhelmed. The output of sensing should not be an “alert” that demands reconstruction. It should be a triggerable hypothesis with enough structure to justify deeper investigation.
Next is selective evidence assembly. When the platform chooses to invest in an investigation, it should retrieve the minimum evidence needed to validate the hypothesis and establish scope. The key is that the system behaves economically and deterministically: it prioritizes high-leverage pivots first, bounds the depth of retrieval, and records what it pulled, when it pulled it, and what assumptions it relied on. This is where platforms separate “activity that looks like a technique” from “risk that matters here,” not by adding enrichment everywhere, but by assembling evidence that supports a decision.
With evidence assembled, the runtime performs adjudication and reasoning. The goal is a decision artifact that can be inspected and replayed, not a binary “fired” outcome. Reasoning should make explicit what the system believes happened, why it matters in this environment, what constraints were violated, and what evidence is missing or uncertain. Critically, reasoning should be able to incorporate reliability signals from the detection pipeline itself. If schemas have drifted or required fields are missing, the platform should degrade confidence and route appropriately rather than asserting precision it cannot support.
Finally, runtime execution culminates in case construction. If the system decides the candidate is worth human attention, it should emit a case-first work unit with a consistent contract: narrative summary, evidence timeline, key pivots, scope indicators, and recommended next steps. This is the handoff point where the SOC stops being a context assembly line and becomes a validation and decision function. When implemented well, this layer is operationally measurable: time-to-decision drops, outcomes become more consistent across analysts, and the organization can safely move up an autonomy ladder because decisions are bounded, explainable, and auditable.
Governance & Continuous Improvement
As detection shifts into a decision runtime, governance must extend beyond traditional change control for rules and playbooks to include the auditability of AI-assisted decisioning itself. The platform’s output contract has to make decisions inspectable and replayable, not just persuasive. In practice, that means every promoted case (and every automated suppression, threshold change, or routing decision) should carry provenance: what evidence was pulled, which context sources were consulted, what policy constraints were applied, and what uncertainty remains. The system also needs reproducibility over time by logging the relevant inputs and the versioned components that produced the result, including model and prompt versions where applicable, so teams can explain why an outcome changed and roll it back safely when needed.
Equally important, governance must treat AI-driven updates as production changes with bounded blast radius. AI-generated detections and tuning recommendations should be versioned, reviewable, testable, and reversible, with clear approval gates that separate read actions from write actions and enforce scoped permissions. Finally, the platform should continuously monitor for decision drift and feedback-loop overfitting by tracking operational metrics such as promotion rates, false-positive cost, time-to-decision, and miss indicators. Without these controls, the SOC risks replacing visible alert noise with a more dangerous failure mode: quiet shifts in what the system chooses to ignore, escalate, or explain.
The first requirement is accountable decisioning. If a platform is going to influence prioritization, case creation, and response, it has to make its decisions inspectable. That means clear provenance for key inputs, audit trails for what evidence was used, and an ability to replay why a case was promoted and why a recommendation was made. In practice, this becomes a product surface: the system must expose assumptions, uncertainty, and missing data rather than presenting a confident narrative that cannot be validated.
The second requirement is change control for the detection runtime. In a case-first model, changes are not limited to detection logic. They include suppression policies, thresholds, routing rules, case promotion criteria, automation eligibility, and investigation workflows. Platforms that scale treat these as production changes: versioned, reviewable, testable, and reversible. Even when AI generates or modifies logic, the organization still needs an audit trail that answers what changed, who approved it, what evidence justified it, and what operational metric it moved.
The third requirement is guardrails for autonomy. As platforms blend investigation and response, control over write actions becomes unavoidable. Systems need approval gates, scoped execution permissions, and policy constraints that limit blast radius. Automation should be explicitly staged, with a clear autonomy ladder that reflects how SOCs adopt change in practice. The goal is not to eliminate human accountability. The goal is to make machine participation safe and measurable so teams can move from assistance to controlled execution without introducing silent failure modes.
Continuous improvement is the companion capability that keeps the decision runtime from degrading over time. Mature platforms establish a closed feedback loop where cases resolve into a small set of outcome states and those outcomes feed back into what the system prioritizes, how it routes, what it promotes into cases, and how it improves decision and case quality over time. In a Phase 4 operating model, that loop must also include coverage integrity. Programs need feedback not only on whether decisions were right, but on whether detection pipelines remain trustworthy as telemetry changes. Over time, the goal is a runtime that converges toward local reality: fewer repeat false positives, fewer silent failures, faster time-to-production for new tradecraft, and more consistent case outcomes across analysts.
Interface + Operating Model
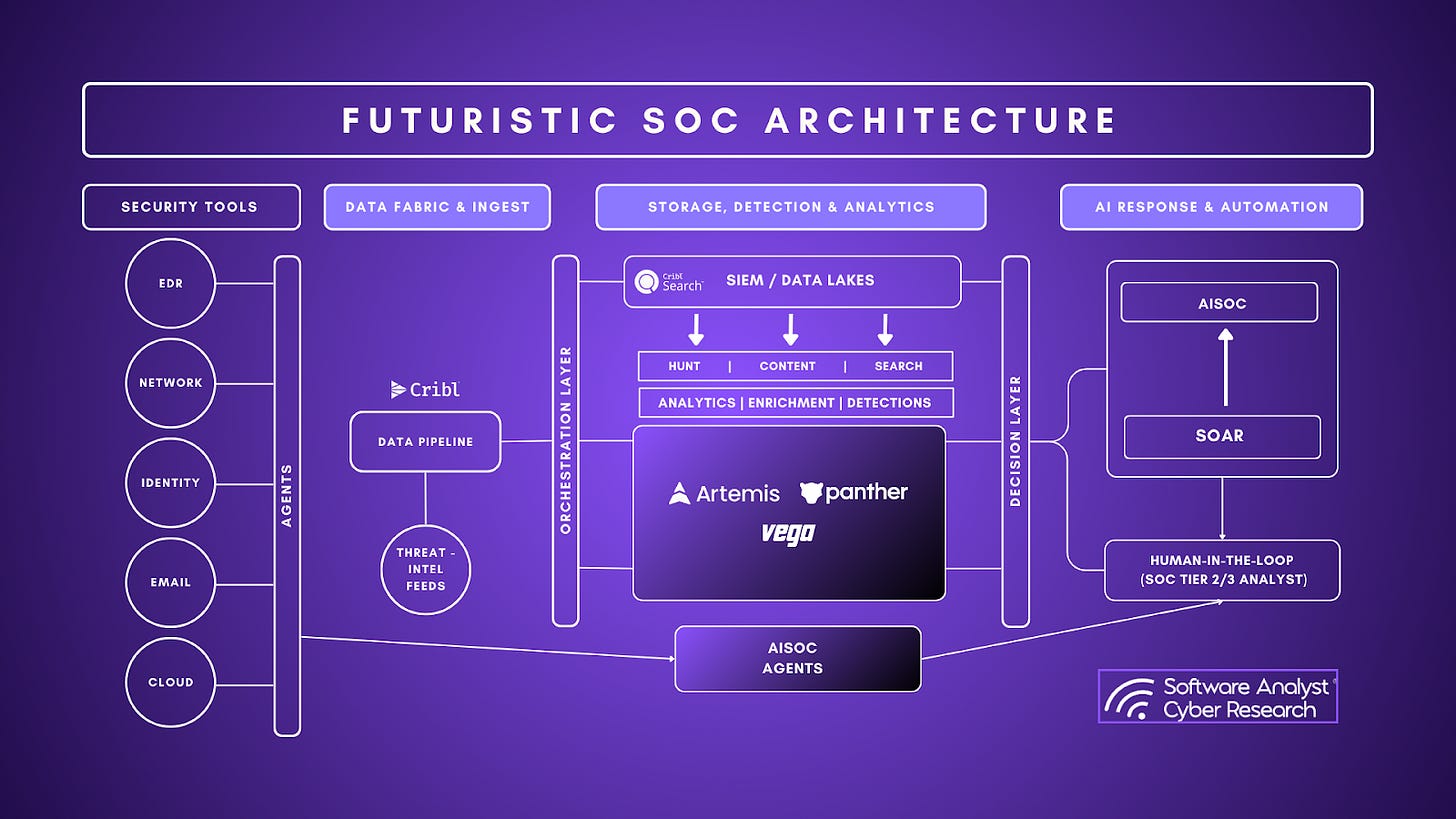
The interface is not a cosmetic detail in next-generation SecOps platforms. It determines whether the SOC can actually operate the decision runtime at scale. The historical interface contract forced analysts to be translators: they expressed intent as queries, stitched timelines manually, and carried institutional context in their heads. In a case-first operating model, the interface has to do the opposite. It has to make intent explicit, reduce the “where do I look next” burden, and keep the system’s decisions reviewable. The goal is not to hide complexity. The goal is to move complexity into the platform so that human effort is spent on validation, tradeoffs, and response rather than on extraction and stitching.
The defining interface shift is intent-driven interaction. Instead of starting with a query language, analysts start with a question: what happened, why it matters here, what else is related, and what should we do next. Natural language becomes a control surface for investigation, but only if the platform can translate that intent into repeatable steps with visible evidence. The system should show what it did, not just what it thinks. When it generates a narrative summary, it should also provide the underlying pivots and artifacts so an analyst can verify the story, disagree with it, or extend it. This is where trust is built: not by confident prose, but by fast access to evidence and clear reasoning boundaries.
The second shift is that the interface is organized around cases as the unit of work. Case-first does not mean hiding alerts. It means that candidates are promoted into durable work units with a stable contract: narrative, evidence timeline, key pivots, scope indicators, confidence, and recommended next steps. That contract enables a different SOC workflow. Work can be assigned, reviewed, escalated, and measured without each analyst reconstructing the same context from scratch. Over time, the interface becomes less about searching and more about navigating decisions: what the system believes, what it used to decide, and what the next action should be.
The operating model changes alongside the interface. In a decision runtime SOC, the human role shifts from “L1 triage factory” to review-and-direct. Analysts validate case promotion, correct assumptions, and decide whether the recommended action is proportional to confidence and impact. Detection engineering shifts from shipping rules to operating a system: managing promotion criteria, routing, suppressions, and response guardrails. This is also where governance becomes day-to-day, not periodic. The same interface that supports investigation needs to support control: who can change thresholds, what gets auto-promoted, which actions require approval, and how the platform logs decisions.
Finally, the interface has to support a practical path toward autonomy. Most SOCs will adopt machine participation in stages, so the product should make that progression explicit: recommend, then assist, then execute under policy. That progression depends on a few interface primitives being consistently present. The system needs to show confidence and uncertainty, provide reversible actions, maintain clear audit trails, and make it easy to measure whether automation is helping or silently creating new work. The end state is not an “AI SOC” that replaces humans. It is a SOC where humans are the governing layer, and the platform reliably turns machine-scale telemetry into decision-grade cases that are faster to validate and safer to act on.
Vendor Analysis
The vendor landscape discussed in this section reflects a broader shift in security operations. The market is moving beyond “more detections” and even beyond detection as code toward systems that can consistently turn weak, high-volume signals into decision-grade outcomes. In practical terms, that means producing fewer but better work items: investigation-ready cases with the minimum necessary context, a coherent narrative, traceable evidence, and clear next steps.
Each vendor is evaluated against the operating model described in this report: a decision runtime SOC where detection is an end-to-end pipeline that must be reliable in production, measurable as coverage, and governed as autonomy increases. Because vendors occupy different layers of the stack, the comparisons are directional rather than one-to-one. Some products are closest to the evidence plane and detection surface. Others focus on federated access and economics, or on upstream context fusion and AI-driven detection generation.
The vendors highlighted here are not an exhaustive survey of the market. They are a representative set of approaches that illustrate the tradeoffs and architectural directions described in this report, and they should be read as options to evaluate rather than a comprehensive list.
Cribl:
Overview
Cribl is a telemetry data management and routing platform used by IT and security teams to gain control over high-volume machine data before it lands in SIEMs, data lakes, and analytics tools.
Its core value in security data pipelines is that it acts as the control plane between telemetry sources and downstream security tools, giving teams precise control over what data flows, how it is shaped, and where it lands. It ingests high-volume security telemetry and then filters, transforms, normalizes, and enriches it (or drops low-value noise) before routing the right subsets to the right destinations such as SIEMs, data lakes/lakehouses, and detection engineering or automation tooling.
Across the market, it’s positioned as a “data pipeline/control plane” layer for observability and security teams. Its portfolio emphasizes three big outcomes:
- Modernizing SIEM and security data pipelines by shaping and distributing security telemetry to tools like Splunk and other analytics platforms,
- Enabling lake/lakehouse-style analytics, storage, and replay workflows for telemetry (supporting offload, temporary storage, and flexible rehydration),
- Governance and economics for telemetry: they protect sensitive data in-flight (e.g., through capabilities like Cribl Guard), improve visibility into data flows and spend (e.g., FinOps-oriented monitoring), and conduct monitoring and alerting on data and infrastructure (e.g., through Cribl Insights).
Cribl Search – Product & Architecture
Cribl released an updated version of Cribl Search in early March 2026. Cribl Search is an AI-native log intelligence solution built on an agentic telemetry architecture for both security and IT operations teams. Cribl Search unifies human-generated context with streamlined log ingestion, storage, and analysis across both Cribl‑managed and external data stores. Using AI-powered parsing, Cribl Search automatically normalizes data at ingest and unifies machine telemetry with human context from tools such as Jira, Git, and ServiceNow so all relevant signals land in one place.
Based on the premise of our earlier report, we believe that SecOps is moving from alert-first operations toward decision-grade work units. We can now have more enriched cases that include narrative, evidence, and recommended actions. That shift changes what matters in the stack. It raises the importance of the evidence plane: where telemetry lives, what is searchable, how quickly it can be retrieved, and what it costs to interrogate during an investigation. Cribl Search is relevant to that thesis as a data-plane and investigation capability, not as a detection engine. Cribl’s approach is to give teams one interface across all telemetry and one search experience, regardless of the type of data or where it’s stored. Teams can query logs, metrics, and other machine data in place across storage tiers and systems, with results unified into a single view accessible through both natural language and KQL-based searches. In environments where evidence is scattered across a SIEM, object storage, cloud analytics services, and SaaS APIs, Cribl Search helps reduce the “evidence retrieval tax” that slows investigations and degrades case quality.
Cribl Search offers a federated engine to search data in-place as well as a new lakehouse engine for optimized access to ingested data sets. Its federated capabilities are designed to query data where it lives (data lakes, object stores, analytics platforms, and APIs) without requiring data to be moved into specialized storage or indexed first, saving organizations time and money. Unlike federated data, data stored in lakehouse engines is automatically ingested and schematized and offers faster analytics performance. Cribl Search is not a full detection platform or a case management system, and it does not replace detection authoring, response workflow, or the governed decisioning layers emphasized in the report. With Cribl Search, analysts now have analysis options that provide agents and humans a single investigation surface over all their data, whether it lives in Cribl Search or in existing lakes and object stores. Performance is a key consideration for federated and archival queries, and Cribl has introduced significant enhancements in this new version.
Cribl Search & The Future of Detections
Cribl Search maps to the report’s argument in three concrete ways. First, evidence accessibility is a prerequisite to case quality: case-first outputs assume an analyst (or an agent) can validate claims quickly by pivoting across telemetry and reconstructing timelines. When relevant evidence sits outside the SIEM (for example, cold storage, alternate analytics platforms, or SaaS APIs), investigations either stall or become shallow, and case construction becomes slower and less consistent. Cribl Search is designed to make more of that “out-of-band” evidence queryable through one interface.
Second, data-plane economics shape what is “detectable” in practice: the report highlights that next-gen platforms must treat cost and latency as first-class constraints, because retrieval that is too slow or too expensive will not be used repeatedly. Cribl Search is explicitly positioned around querying data where it already lives, including low-cost storage tiers, to avoid ingest-first economics.
Third, investigation workflow primitives matter beyond one-off queries: Cribl Search includes workflow constructs that are relevant to “case construction,” such as saved searches, dashboards, scheduled searches or notifications, and Notebooks for packaging searches and notes into a shareable investigation artifact. These do not equal a case system, but they are adjacent capabilities that can reduce the time it takes to assemble and communicate investigative findings.
Product and Technical Notes
Cribl Search offers a federated engine and a lakehouse engine. The federated engine allows users to search data in-place across object storage, data lakes, and cloud services. The lakehouse engine to run fast searches on frequently accessed telemetry. With both engines, Cribl Search leverages natural language or KQL. The federated engine translates queries to the underlying provider mechanics as needed, then combines results into a unified view. In its documentation and product messaging, Cribl describes broad evidence-plane coverage across data lakes and object stores (including Amazon S3 and compatible stores, Azure Blob Storage, and Google Cloud Storage), analytics services and platforms (including Azure Data Explorer, Elasticsearch or OpenSearch, and Prometheus), cloud data warehouses (including Snowflake and Clickhouse), and API endpoints (including AWS, Azure, Google Workspace, Okta, Zoom, and a generic HTTP API options). It also describes integration with Cribl Stream and Cribl Edge. Cribl also emphasizes a “results as data” pattern in which search results can be routed to downstream destinations, including Stream-based processing and routing.
Competition and Positioning
For the purposes of this report, Cribl Search competes or overlaps with SIEM incumbents that extend search into cheaper storage tiers or provide their own federated querying, cloud-native analytics stacks when an organization standardizes on a single lake plus query service, and other federated search fabrics with security hunting and investigation positioning. The key comparative question in a case-first narrative is not “who has the most features,” but whether federated evidence retrieval is consistent and operationally usable enough that teams will rely on it during investigations.
Implications for the case-first, decision-runtime SOC
If Cribl Search works as intended in practice, it can expand what evidence is reachable during an investigation without forcing ingest-first architectures, reduce time-to-evidence when cases require pivots across cold storage or external systems, and support repeatable investigation artifacts (for example, notebooks and saved searches) that can be referenced during case write-ups or handoffs. Key open questions to validate include whether performance varies materially by provider, data format, and time range, how much operational work is required to make cross-source pivots dependable, and whether access controls, auditing, and permission boundaries meet SOC requirements when querying sensitive sources (especially SaaS admin APIs and audit logs).
Panther:
Overview
This report’s core argument is that SecOps is moving from alert-first operations toward decision-grade outcomes, where the unit of work is an investigation-ready case: evidence, timeline, entities, and recommended next steps. Panther is relevant to that thesis as a platform that sits close to the “traditional SIEM” role but tries to modernize the detection workflow and, increasingly, the investigation loop. Its core bet is that security teams should be able to manage detections with software rigor and iterate quickly without the usual SIEM friction, while still retaining control over where data lives and how it is processed.
Panther is consistently framed as a next-generation SIEM centered on detection engineering. The platform’s architecture emphasizes a security data lake model where compute and storage are separated, commonly leveraging cloud storage layers such as Databricks and Snowflake. In practice, this design is meant to keep retention and scale manageable while supporting real-time detection and investigations, rather than forcing teams into a single monolithic analytics stack.
Panther – Product & Architecture
Panther has evolved from its cloud-native SIEM foundation into an AI SOC operating model — where agents become a first-class layer in daily SOC work. The platform narrative is that the system should sit close to the evidence plane and the detection surface area, then use AI to compress the “interpretation and assembly” steps that normally live in human triage, moving the SOC toward investigation-ready outputs and faster, more consistent decisions.
Panther’s alert triage agent is positioned as an always-on workflow that evaluates each alert and returns a structured investigation artifact rather than just a severity label. The output is described as a comprehensive report with an activity summary, an evidence-backed risk classification, key findings, and recommended next steps, so the analyst’s job shifts from “reconstruct what happened” to “validate and direct,” which is aligned with a case-first operating model.
Panther’s approach treats context as a decision dependency, it supports ingesting from common SaaS and identity sources, extracting indicators and entity attributes into consistent fields, and enabling fast correlation across users, devices, and artifacts. The intent is to make pivots repeatable and cheap, so investigations do not collapse into manual cross-tool lookups every time an alert fires, and so the platform can selectively retrieve the context needed to justify deeper work.
Panther frames detections as more than logic, a detection is presented as logic plus the surrounding threat model, risk criteria, and guidance that can be acted on consistently. A key “who they are” detail is the shift toward runbooks written to support AI-assisted investigation and decisioning, using criteria-based direction rather than long checklists, which helps encode analyst intent in a form that can be governed, reviewed, and iterated like software.
Panther describes MCP server integrations as a mechanism for extending investigations beyond the SIEM boundary into external systems where relevant context or workflow artifacts live. The implementation is positioned around an OAuth-style connection flow and explicit permissioning that separates read from write actions, enabling the platform to pull relevant context or write back investigation outputs (for example into Notion) while keeping autonomy bounded, auditable, and compatible with human approval gates.
Panther includes a feedback system where alert outcomes are labeled with quality semantics (framed as “noise” versus “useful”) and then reused to improve future triage and tuning decisions. This is presented as a practical way to “close the loop” operationally: each investigation should not only be resolved, but should generate structured learning that reduces recurring workload and tuning debt over time.
Panther introduces scheduled prompts as a detection and governance primitive that can run on a cadence to surface behaviors, validate assumptions, or audit prior automated decisions. In a decision-runtime framing, this is a way to make “continuous verification” part of SOC operations: the platform can periodically re-check what it auto-classified or auto-resolved, and can use those audits to improve reliability and trust as teams move up an autonomy ladder.
Automation is presented as optional and staged, with configurable thresholds and customer-dependent risk tolerance determining how far teams go beyond assistance. The key implementation idea is that autonomy is not a binary switch: the platform can start with recommendations and structured triage outputs, then move toward limited auto-resolution or escalation under explicit guardrails, with monitoring and audit patterns designed to prevent silent failure and keep decision-making reviewable.
Why it shows up in a “Beyond Detection as Code” narrative
Panther maps to the report’s argument in three concrete ways.
First, Panther operationalizes the idea that detection content should be treated like software. This is the most direct bridge from “detection as code” into more agentic futures: if the detection layer is already versioned, testable, reviewable, and deployable, then it becomes more feasible to introduce AI-assisted authoring and tuning without losing governance, because Panther’s detection layer is built in Python, the native language of AI, the platform can comprehend, generate, and optimize detection logic more efficiently as compared to proprietary rule languages.
Second, Panther’s approach makes “change velocity” a first-class requirement. One of the recurring practical problems in SOCs is that the environment changes faster than detections and tuning. A platform designed around rapid iteration, testing, and rollback is structurally better suited to the closed-loop “detect → investigate → learn → tune” cycle than systems that treat detections as UI-configured artifacts with limited lifecycle tooling.
Third, Panther has positioned AI as part of the investigation and tuning loop, not just a convenience feature. Panther’s public messaging emphasizes “closing the loop,” and frames the goal as AI-assisted investigation, tuning, and safe autonomy. The important claim is not that AI closes alerts for you, but that each investigation can produce feedback that improves future detections and reduces repetitive noise.
Product and Technical Notes
On ingestion and data management, Panther supports multiple methods of getting data into the platform and normalizes logs into structured schemas with extracted indicator fields. A concrete feature discussed in briefings is schema inference for new or unknown sources using a “holding tank” pattern, where events can be buffered until a schema is inferred and attached. The platform also supports filtering and enrichment, with an emphasis on reducing noisy sources while retaining investigation utility.
On detection, Panther’s differentiator is its detection-as-code model, with Python-based rules as the flagship interface and support for testing, version control, and CI/CD workflows. The system supports streaming or near-real-time detection and can enrich investigations with lightweight signals and extracted indicators. Panther is also layering in AI capabilities that help generate detection logic, tests, and queries from natural language, with the intent of reducing detection engineering overhead.
On investigation, Panther is oriented around making it easier to correlate and validate what happened by pivoting across entities and timeline context. Emphasizing triage support, summaries, recommended next steps, and the idea that claims should be verifiable with underlying artifacts.
Competition and Positioning
For the purposes of this report, Panther overlaps with three adjacent buckets. It overlaps with cloud-native SIEMs and “data lake SIEMs” that separate compute from storage and prioritize scalability. It overlaps with detection engineering platforms that provide strong authoring and lifecycle workflows for detection content. And it increasingly overlaps with AI SOC positioning where the differentiator becomes investigation assistance and closed-loop learning.
The differentiator Panther is aiming for is a blend: a modern cloud SIEM foundation, developer-friendly detection lifecycle, and an AI layer that reduces tuning debt and accelerates investigations. If that holds, Panther can function as a practical anchor vendor in the report because it touches the core detection and monitoring surface area where most SOC teams already spend time, while also illustrating the direction of travel toward more agentic investigation and tuning.
Implications for the case-first, decision-runtime SOC
If Panther works as intended, the practical impact is that it can make investigation outputs more consistent and detection changes more governable. In a case-first narrative, the key benefit is not simply “faster alerts,” but a higher likelihood that investigations are repeatable and that learnings are translated into concrete changes in the detection layer rather than remaining tribal knowledge.
Key open questions to validate include how well Panther’s AI features preserve explainability and provenance under real-world pressure, whether the closed-loop tuning story translates into measurable noise reduction without creating blind spots, and how organizations with varying levels of detection engineering maturity adopt the detection-as-code workflow without shifting the operational burden elsewhere.
Vega:
Overview
This report’s core argument is that SecOps is moving from alert-first operations toward decision-grade outputs, where investigations rely on fast pivots across evidence that is often distributed across systems and storage tiers. Vega is relevant to that thesis because it frames the bottleneck as data access and economics rather than detection logic alone. The platform’s premise is that teams should be able to search, correlate, and detect across all security data without being forced into a single ingest-and-store architecture.
Vega’s positioning emphasizes “federated search” and broad access to security telemetry across storage locations, including object storage that historically sits outside the SIEM due to cost and friction. In that framing, the value is not only faster hunting, but the ability to use more of the organization’s existing data footprint, including cold or underutilized “blind” data, to improve investigations and coverage.
Vega – Product & Architecture
Vega is a federated security analytics and detection platform designed to let SOC teams query, correlate, and operationalize detections across security data that already lives in multiple places, including existing SIEMs, data lakes, and object storage. Their core bet is that modern SecOps breaks down less because teams lack detections, and more because evidence is fragmented across tools and storage tiers, making investigations slow, expensive, and inconsistent.
At the platform layer, Vega provides a single query experience centered on KQL. Analysts write KQL once, and Vega translates and executes it against connected backends (Splunk, Elastic, Google SecOps, Sentinel, etc.) so teams do not have to pivot between consoles or maintain multiple versions of the same investigative query and detection logic. Vega emphasizes that this translation uses static mappings, and not AI to keep execution repeatable and predictable.
A second major component is Vega’s object storage indexing architecture, which is intended to turn low-cost storage into investigation-grade evidence. Vega deploys indexing infrastructure in the same cloud and region as customer data, parses incoming logs into key-value representations, indexes and compresses them, and writes the result into an “index bucket” so data becomes searchable quickly. Customers can host this storage in their own cloud for ownership and retention control, or use a Vega-hosted SaaS model.
On top of search, Vega positions itself as a detection engineering and detection operations layer. Detections are authored in a notebook-style, multi-cell format where teams can build reusable logic blocks, union/join results across sources, and designate trigger cells that define when alerts fire. This structure supports detections that combine signals from different telemetry sources and supports enrichment and tuning without rewriting the original logic. Vega also maintains a vendor-agnostic detection library that is written to data types and normalized fields so detections can survive product changes and apply across multiple EDR vendors when the underlying event semantics are present.
Vega’s approach to field consistency is to keep raw fields always available while layering OCSF-aligned normalized views at query time. Vega uses LLMs with human approval to create and validate these mappings, with a stated timeline of 1–2 days for common sources and up to a week for more custom sources. In parallel, Vega supports natural language to KQL to help analysts generate searches and starting-point detections, then iteratively run, validate, and refine them.
Vega also uses MITRE ATT&CK mapping as an operational coverage surface, not just a reporting artifact. The product provides a coverage heat map that shows which techniques have active detections, highlights blind spots where the environment lacks applicable data, and updates frequently described as hourly polling of MITRE. For uncovered techniques, Vega can generate candidate detections, run and refine them, then present them as starting points a team can validate and deploy.
Finally, Vega includes a threat intelligence dashboard intended to shorten time-to-coverage when new threats emerge. Vega publishes research-team-created intel reports that include summaries, extracted IOCs, recommended log enhancements, and suggested Vega detections tied to the customer’s connected data sources. It also supports user-contributed intel, where teams upload a URL or PDF and Vega generates a report in about 60–90 seconds, extracting IOCs, identifying telemetry gaps, and generating detection content mapped back into the platform’s workflows, with visible reasoning steps for review.
On top of alerting, Vega is also building toward case-first operations by adding AI-driven triage and investigation. In a product demo, Vega showed AI triage promoting alerts into incidents, producing a conclusion with key findings, and transparently exposing the exact queries and steps the AI ran so analysts can review and reproduce the investigation, copy queries into notebooks, and validate the decision trail.
Why it shows up in a “Beyond Detection as Code” narrative
Vega maps to the report’s argument in three concrete ways.
First, it reinforces the shift from “alert generation” to “case construction” by prioritizing broad evidence access. In a case-first SOC, investigations fail when the relevant telemetry is inaccessible or prohibitively expensive to retrieve. Vega’s model aims to reduce that evidence retrieval tax by making more sources queryable without a migration-first program.
Second, it aligns with the view that the detection layer is increasingly a fabric that spans multiple systems. The platform’s internal framing includes a “detection fabric layer” where KQL is used as an interface, and normalization is oriented around OCSF. That approach supports a world where detection content and investigative queries are designed once and executed across heterogeneous data sources.
Third, it reflects the growing role of AI in turning broad data access into operational leverage. Vega’s external messaging emphasizes unified, AI-powered detection and “AI-native analytics,” which fits the report’s thesis that human effort shifts from writing syntax to steering investigations, validating evidence, and improving the system through feedback loops.
Product & Technical Notes
Vega emphasizes federated search and a unified query experience across distributed telemetry. A recurring theme is meeting data in object storage and enabling indexing where needed, which is intended to make cold or underused telemetry operationally useful for security teams.
The platform’s described design includes a KQL-oriented interface and normalization to OCSF, which supports consistent fields and pivots across sources. Vega’s messaging also points to workflow support across detection, assessment, search, triage, and response, with threat intelligence and tuning positioned as integrated capabilities. In combination, this suggests a product direction that treats “data decentralization” as the default condition and builds detection and investigation workflows on top of it rather than attempting to remove it.
Competition and Positioning
For the purposes of this report, Vega overlaps with federated security analytics layers, modern SIEMs that extend into low-cost storage tiers, and platforms that sit on top of data lakes or object stores to provide faster query and correlation. It also overlaps conceptually with vendors that provide an “evidence plane” interface for investigations, where the differentiator is whether broad data access is reliable and fast enough to support day-to-day SOC work.
The differentiator Vega is aiming for is a combination of federated access, simplified operations, and economics that allow teams to expand coverage without committing to ingesting every byte into an expensive analytics tier. If the model holds, Vega becomes especially relevant in environments where the SOC already has meaningful data outside the SIEM and needs a practical path to make that data usable for detection and investigations.
Implications for the case-first, decision-runtime SOC
If Vega works as intended, it can expand the evidence available during investigations, reduce blind spots created by cost-driven ingestion decisions, and improve the speed of pivots needed to build decision-grade cases. It also may change how teams think about detection coverage by making it more feasible to hunt and detect in data that previously sat outside the SOC’s operational reach.
Key open questions to validate include how dependable cross-source normalization is as schemas evolve, how predictable performance is when searching large ranges of object storage, what infrastructure and operational footprint is required to sustain the “federated” model at scale, and how governance, access control, and auditing are enforced when analysts can query sensitive sources across the organization.
Artemis:
Overview
This report’s core argument is that SecOps is moving from alert-first operations toward decision-grade outputs: investigation-ready cases that combine narrative, evidence, and recommended next steps. Artemis positions itself as an AI-native protection and detection layer that generates environment-specific detections and investigative context through agentic workflows, with natural language as the primary interface. It is relevant to that thesis as an upstream detection and context engine: a system that continuously maps the environment, understands what “normal” looks like in the greater organizational context of users, and systems, and generates detections that are both more tailored and easier to evolve than static rule packs.
Artemis frames the problem as an operational mismatch between how modern environments change and how detections are traditionally authored. In classic detection engineering, teams either rely on generic libraries (high noise, constant tuning) or adopt “detection as code” (better rigor, but high engineering overhead). Artemis’ bet is that agents and LLM-driven workflows can absorb much of that overhead. Instead of expecting the customer to continually write and maintain a large portfolio of rules, the platform aims to generate and tune detections continuously based on observed environment context, while still giving customers enough transparency to trust the output. Once a detection fires, it enriches it with business context, investigates autonomously by correlating activity across every log source, and delivers a complete case narrative with recommended response actions. The security analyst then picks up the case where decisions are needed.
Artemis – Product & Architecture
Artemis positions itself as an AI-native detection and protection platform that augments existing SIEM and SOAR in a single unified system. It is designed for an era where attacks unfold in seconds or minutes and the traditional chain of tool alerts to human response is too slow to matter.
In practice, Artemis aims to replace alert-by-alert workflows with case-first SecOps by providing deeper context per log source and across them. This capability is an environment-intelligence layer that sits above raw ingestion and turns each source (Okta, AWS, endpoint, network, SaaS, custom apps) from a flat stream of events into a set of entities, relationships, and behavioral baselines that the platform can reason over consistently across the whole environment. Instead of treating Okta logs as “authentication events” and AWS logs as “API calls” in isolation, Artemis tries to normalize them into a shared model of “who/what did what, to which resource, from where, using what credentials, with what historical baseline,” then uses that model to automatically assemble timelines and cases.
Case Studies of log source context
- For an identity source like Okta, the raw log line (login success/fail, MFA challenge, admin action, OAuth token issuance) becomes enriched with identity role and organizational meaning: this user is helpdesk vs. engineer vs. finance; this account is privileged; these groups imply access to certain systems; this MFA pattern is typical/atypical for this person; these devices and geographies are normal/abnormal; and this action is high-impact because it changes policy or creates new trust relationships. When Artemis says it “understands your environment,” this is the kind of understanding it is aiming for. Identity events aren’t just counted, they’re interpreted in the context of what that identity normally does and what it is allowed to do.
- For a cloud source like AWS (CloudTrail, VPC Flow Logs, GuardDuty-like signals, etc.), the platform’s context layer maps cloud events to the real structure of the environment: which AWS account and business unit it belongs to, what a workload typically talks to, which IAM role is supposed to call which APIs, what “normal” looks like for S3 access patterns or STS role assumptions, and which resources are crown jewels (prod databases, sensitive buckets, CI/CD roles). That’s how a single API call becomes meaningful: the same “AssumeRole” event is routine in one pipeline but suspicious if it shows up from a never-before-seen principal, in a new region, chained to unusual follow-on actions.
Artemis starts from raw telemetry (not just pre-filtered upstream alerts), correlates activity across identity, cloud, endpoint, network, and application sources, and then produces contextualized “cases” that read like complete attack stories. These timelines tie together entities, behaviors, and signals into something an analyst can act on immediately, rather than forcing them to stitch together dozens of disconnected detections.
A key strength in this design is visibility into the full signal stream, including lower-confidence events that many “AI SOC” layers never see because they only consume the high-confidence alerts surfaced by tools like EDR. The crux is that losing those weak signals harms fidelity and makes it harder to reconstruct what actually happened end-to-end.
Finally, Artemis is explicitly built to compress the detection engineering lifecycle and remove dependence on query languages like SPL/KQL by using agentic and natural-language workflows to generate, adapt, and operationalize detections against the customer’s specific environment, so teams can move from an idea or threat report to useful detections or full threat hunt in hours or minutes rather than weeks of manual tuning and iteration.
In summary, Artemis is positioned as an AI-native protection layer with emphasis on detection generation, tuning, and context fusion. Its model is to build a continuously updated picture of the customer environment, then use that context to generate large volumes of custom detections on an ongoing basis, tune those detections as the business and telemetry change, and enrich them with the context needed for faster validation and investigation.
It is not primarily a log pipeline, storage layer, or a traditional SIEM replacement. It also is not the same category as a downstream case management system or SOAR. Artemis sits earlier in the workflow: it tries to improve the quality and adaptability of what gets detected and why it matters, so that downstream triage and response systems receive higher-fidelity starting points.
Why it shows up in a “Beyond Detection as Code” narrative
Artemis maps to the report’s argument in three concrete ways.
First, it treats organizational context as a first-class dependency for detection quality. Artemis emphasizes that effective detection needs both semantic or structural context (what assets are, what they are for, and how they relate) and behavioral context (what users and systems typically do). The practical implication is that detections cannot be reliably “portable” across organizations without becoming either too generic (noisy) or too brittle (high-maintenance).
Second, it reframes the interface and workflow for detection engineering. Rather than making “writing rules” the customer’s primary workload, Artemis aligns with the idea that natural language becomes the primary interface for intent. The platform still needs strong foundations underneath, such as versioning, validation, and safe deployment mechanics, but the day-to-day work shifts toward expressing goals, reviewing outcomes, and steering the system’s learning loops.
Third, it pushes toward closed-loop tuning as the default operating mode. A recurring pain point in traditional rules is operational drift: environments change, logging changes, and attackers change, but the rule corpus does not keep up without ongoing manual maintenance. Artemis’ approach is designed to generate and tune detections continuously, with evaluation and customer control points, so noise reduction and fidelity improvements are not an occasional project but an always-on capability.
Product and Technical Notes
Artemis emphasizes ontology building and relationship understanding so the platform can learn how assets, identities, and behaviors connect in a specific customer environment. It also emphasizes rich enrichment that feeds detection generation and investigation, so detections arrive with enough surrounding detail to validate what happened and why it matters. The platform is described as producing detections daily at scale, rather than relying on occasional rule library updates, and it stresses transparency and controllability so customers can trust AI-driven outputs.
A useful way to frame Artemis in the stack is as a system that tries to make “custom detection at scale” economically and operationally realistic. In that framing, the real product surface is not just a UI, but the end-to-end loop: environment mapping, detection generation, evaluation, tuning, and the ability to hand off detections and context to the rest of the SOC.
Competition and Positioning
For the purposes of this report, Artemis overlaps with detection-as-code platforms that offer rigor and developer workflows but still require the customer to author and maintain substantial logic, AI-native detection platforms that use agents to investigate or triage (especially if they also generate or tune detections), and SIEM vendors that add AI features to existing rule frameworks, particularly if they can incorporate deep environment context.
The differentiator Artemis is aiming for is not “more rules” but more personalized and adaptive detection with lower customer burden. If successful, it positions Artemis as a high-leverage layer that raises fidelity upstream, enabling downstream triage and response vendors to do better work with less noise.
Implications for the case-first, decision-runtime SOC
If Artemis works as intended, the main impact is upstream: it could reduce the chronic SOC tax of tuning and maintaining detections, and increase the share of detections that arrive with enough context to support quick validation and investigation.
Key open questions to validate include how Artemis demonstrates and audits the reasoning behind AI-generated detections in a way that satisfies SOC governance requirements, what the operational model is for customer control and change management for generated detections and tuning changes, how well the platform handles telemetry gaps and “silent failure” conditions where missing logs could make detections appear clean while coverage is degraded, and how portable the system is across different logging architectures and maturity levels without requiring heavy professional services.
Additional Platforms Converging on the Decision Runtime
Spectrum Security
Spectrum automates detection engineering end to end on top of existing SIEM infrastructure. Using read access and current detection rules, it identifies coverage gaps across asset domains, ATT&CK, and active campaigns, then generates tuned, production-ready detections in the customer’s query language for human approval.
The relevance of the decision runtime is operational rigor, not more content. Spectrum tunes recommendations against recent alert history, surfaces cost and volume tradeoffs, and makes its investigative work visible so teams can inspect recommendations before scaling autonomy.
Brava Security
Brava Security is a threat-driven telemetry layer that sits alongside existing data pipelines and SIEMs. Using continuous, agentless attack simulation for logs, it shows how real attacker behavior appears in telemetry, where coverage fails, and what must change upstream to make detection credible. Instead of adding another rules pack, Brava maps behaviors to MITRE ATT&CK, identifies detectability gaps, and drives event- and field-level routing decisions such as filtering, enrichment, deduplication, and tiering so teams keep what matters and stop paying to index noise.
What makes Brava different is the combination of pipeline control and a living “VirusTotal for logs” knowledge base, with intelligence on log signatures, including obscure and undocumented APIs. That turns telemetry strategy from heuristic cost cutting into a measurable security outcome. Brava fits alongside incumbents like Cribl and major SIEMs, acting as the intelligence layer for what to collect and where to route it, without requiring a rip-and-replace.
Strategic Recommendations for Security Leaders
Security leaders should treat the shift to the decision runtime as an operating model change, not a tooling refresh. The goal is to reliably produce decision-grade cases while keeping workload sustainable, and to do it in a way that preserves trust through reliability and governance. That starts with redefining success. Optimize for faster, more consistent decisions and outcomes, not for alert volume or technique mapping. ATT&CK remains a useful taxonomy, but maturity should show up in time-to-decision, time-to-disposition, and the share of outputs that arrive as investigation-ready cases with clear next steps.
Because every detection output consumes analyst attention, leaders should put an explicit price on work. New detections, content, and automation should be gated on a simple question: will this create operational leverage, or operational churn? That framing also clarifies the order of investment. Before betting on AI triage, fund the evidence plane like production infrastructure so cases can be validated quickly and repeatably. If entity resolution is weak or pivots are slow and inconsistent, the SOC will revert to manual reconstruction regardless of how advanced the detection layer appears.
At scale, reliability engineering is non-negotiable. Assume detections will silently fail as schemas and pipelines drift, and require continuous validation with clear coverage-health signals and time-to-repair metrics. Operating a decision runtime also means separating sensing from decisioning so cheap, high-recall sensing does not automatically trigger expensive investigations. Promotion into cases should be bounded by explicit thresholds and evidence requirements that keep workload sustainable.
Finally, leaders should govern the runtime, not just the rules. Runtime policy should be versioned, reviewed, and audited as autonomy increases. Autonomy should be adopted in stages, from recommendations to assistance to scoped execution, and advanced only when it measurably improves outcomes and failure modes are understood. Over time, the program should get cheaper to operate, which means capturing structured case outcomes and using them to reduce churn, rework, and tuning debt rather than simply generating more detections.
Practitioner Takeaways
For practitioners, the core shift is to treat detections as an end-to-end decision system, not a library of rules. Optimize for a smaller number of consistent, investigation-ready cases, not a larger stream of alerts. In practice, design each detection to answer three questions quickly: what happened? Why does it matter here? and what to do next? with enough attached evidence that the decision can be validated instead of re-discovered.
Make operational value versus operational burden the daily tuning lens. A detection that does not reliably create leverage is not neutral. It consumes attention, creates backlog pressure, and increases the odds of missed prioritization elsewhere. Track what repeatedly burns time, produces dead ends, or forces manual context reconstruction. Use that data to suppress, rewrite, or retire detections with high cost and low decision yield.
Build for repeatability and drift. Prioritize evidence quality and consistent pivots across identities, assets, and workloads. Standardize a case packet that includes detailed narrative, evidence, key entities, indicators, and clear next steps. To account for silent failure caused by pipeline and schema drift, prioritize coverage health visibility to distinguish between a lack of activity and a broken rule. Push autonomy in stages starting with case drafting and recommendations with provenance, expand to bounded investigative actions, and reserve execution for scenarios with explicit guardrails, approvals, and explicit rollback capabilities.
Conclusion
The market is moving beyond Detection as Code not because engineering discipline failed, but because disciplined rule authoring alone cannot solve SecOps’ scaling constraint: turning high volume weak signals into consistent, reviewable decisions. As the unit of work shifts from alerts to cases, distinction shifts to execution. Winners will be the platforms that can reliably convert telemetry into decision grade cases with evidence, narrative, and clear next steps, while human analysts maintain the accountability for prioritization and response.
Case-first is also the practical bridge from today’s detection engineering lifecycle to the decision-runtime future. Teams will still author, test, and tune detections as environments and tradecraft change, but the output becomes the forcing function. Sensing is separated from deciding, decision dependencies are retrieved on demand, and thresholds for promotion and suppression become the new engineering surface. In that world, better detection is no broader mapping or larger libraries. It is higher leverage per case, measured in time-to-decision and outcome consistency, backed by integrity, and governed autonomy that is auditable, reversible, and policy bound.