Author: Aqsa Taylor is the Chief Research Officer at SACR. She is a published author of two cybersecurity books and comes with a strong background in Cloud Security and SecOps.
Co-Author: Chi Aghaizu is Founding Engineer and Research Assistant at SACR with an experience in building AI platforms for security.
Quick Read:
Here’s quick insights on the report –
1. Market Consolidation Accelerates with Acquisitions
The SDPP market is entering a rapid consolidation phase as major SIEM, XDR, and observability providers acquire pipeline platforms to strengthen their data architectures. Recent deals include CrowdStrike acquiring Onum for about 290 million dollars, SentinelOne acquiring Observo AI for approximately 225 million dollars, Panther Labs acquiring Datable for an undisclosed amount, and now, Palo Alto Networks announced acquisition of Chronosphere, for $3.3B dollars (one of the biggest in the industry). These acquisitions reflect a clear industry trend. Large security and observability vendors are absorbing pipeline capabilities to overcome long-standing ingestion, normalization, and cost challenges within their own platforms. Buying is proving faster and more strategic than building, and this shift is moving the center of gravity in the SOC toward the pipeline layer.
But what does this mean for the vendor neutrality benefit that security data pipelines have long been known for? Practitioners express concerns about vendor neutrality, migration bottlenecks, and more in this report.
2. Security Data Pipelines Have Become the SOC Control Plane
Pipelines no longer simply move logs. They now govern ingestion, normalization, enrichment, routing, tiering, and data health. As a result, they have become the primary control plane of the modern SOC. Every downstream system relies on them for clean, consistent, and trustworthy telemetry. In this report, you’ll find an indepth valuation of core capabilities and emerging innovation in the security data pipeline market.
3. AI Is Becoming Essential for Pipeline Operations
AI adoption is practical, assistive, and explainable. Security teams want AI that handles engineering-heavy or repetitive work such as parser creation, schema drift correction, pipeline generation, baselining, and anomaly detection. Teams aren’t comfortable yet with autonomous decision-making in the SOC but strongly support AI within pipelines to reduce workload and increase consistency in pipeline operations.
4. Telemetry Health Monitoring Is Now Critical
Security teams express more fear of missing data than of noisy data. Pipelines now provide intelligent, continuous telemetry health: silent source detection, schema drift, volume anomalies, baseline deviation, noisy source spikes, and rerouting options based on destination failures. This monitoring in the data layer ensures the SOC never operates blind.
5. Shift Detections Left
Some platforms are pushing detections into the pipeline, performing lightweight IOC checks and early pattern recognition before events reach the SIEM. Practitioners value earlier context but note that response speed, not detection timing, often limits real impact. Learn more about how this trend is shaping impressions within the security community.
6. Pipelines Form the Foundation for AI Driven Security Operations
AI systems depend on high-quality, normalized, enriched, and complete data. Pipelines are becoming the preparation layer for AI copilots, LLM-based SOC assistants, advanced correlation engines, and autonomous triage. Without pipelines, AI performance degrades significantly. This makes SDPPs a strategic enabler for future SOC automation.
7. SDP PLUS Vision
In addition to core pipeline features, we are seeing a trend in which pure-play SDP platforms aim to expand horizontally across the SOC stack by taking on adjacent category capabilities beyond traditional pipeline functions. These include in-house data lake options with tiered storage, threat detection and analytics at the pipeline layer, federated search and querying across SIEMs and data lakes, observability convergence, and AI SOC-like capabilities.
Summary for Security Leaders
Security data pipelines are now the control plane of the modern SOC. They own data and deliver cost efficiency, improved data quality, faster investigations, cleaner enrichment, better telemetry reliability, and vendor-neutral routing. They are also becoming the data foundation needed for next-generation AI-driven operations. As acquisitions accelerate, the market is shifting toward two branches: standalone security data pipeline platforms and SDP capabilities within broader architectures. Either direction underscores the importance of the data pipeline as the most critical layer in the security stack.
Introduction
Before diving into this report, it’s important to set some context for readers who are learning about security data pipeline platforms (abbreviated as SDPP throughout the report). In Francis’s first report, The Market Guide 2025: The Rise of Security Data Pipeline Platforms, he introduced what these platforms bring to the world of security operations. It was the first analyst report focused on this category, even though the solution had existed for years. Their rise was largely driven by practitioner concerns about legacy SIEM platforms and ongoing issues with data quality. I explained the practitioner concerns in detail in my Convergence of SIEM Platforms report, where I also highlighted how two major SIEM vendors acquired security data pipeline companies to redefine SIEM capabilities through pipeline integration. Since then, there has been another acquisition by Panther of the Datable.io security pipeline platform. And as of today, November 19th, Palo Alto Networks announces acquisition of Chronosphere.I expect we’ll continue to see more of these acquisitions soon as SIEM vendors race to outpace legacy limitations and evolving practitioner concerns.
In this version of the report, we take a deep dive into the world of security data pipeline platforms, exploring how the category has evolved over the past year and the different directions vendors are now taking. The focus is on mapping how these platforms have matured in both capability and purpose, moving from basic data routing tools to core components of modern security architectures. This report expands on the original framework with a new layer of analysis that explores several key pipeline capabilities in depth, taking into account both the breadth and the maturity of the features.
The report further captures the different paths SDP vendors are taking, from those deepening their integrations with SIEMs as data routing platforms to those moving toward in-house data lake capabilities in a vision to rise as “SDP PLUS” platforms. It draws from practitioner conversations, customer interviews, and in-depth briefings to provide a grounded view of how these platforms are being adopted and adapted within real SOC environments.
Revisiting the SDPP Report version 1: How the Data Layer Became the Heart of the Modern SOC
In our first report, we defined what Security Data Pipeline Platforms are –
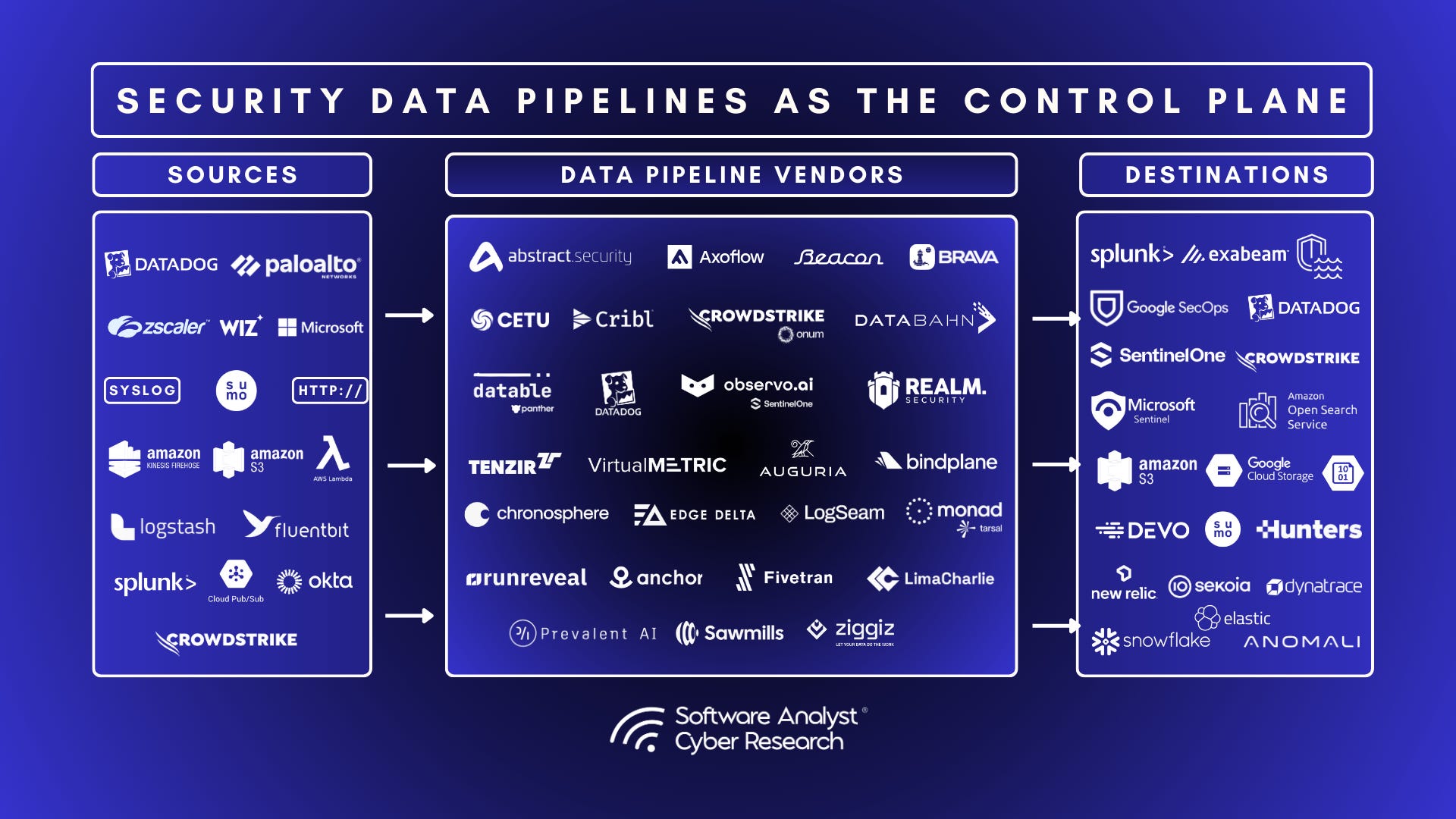
Security Data Pipeline Platforms (SDPP) are purpose-built systems that ingest, normalize, enrich, filter, and route large volumes of security telemetry across hybrid and cloud environments. These platforms sit between data sources (like EDRs, cloud logs, and firewalls) and destinations (like SIEMs, data lakes, XDRs, and analytics tools). Their goal is to optimize the flow and quality of telemetry data to reduce operational complexity and cost while increasing the speed and accuracy of detection and response.
When the Security Data Pipeline Platform (SDPP) report was first published, it drew attention to something that many security teams had quietly been feeling for years. SIEMs were reaching a breaking point, yet, not disappearing. As organizations collected more data, the traditional model of ingesting everything was becoming impossible to sustain. The report highlighted that this shift marked a deeper transformation in how modern Security Operations Centers (SOCs) would be built with the introduction of security data pipeline platforms in the data fabric.
At the center of the report’s findings was the rise of the SDPP. These platforms were described as a new foundational layer in the SOC, sitting between data sources and destinations like SIEMs, data lakes, and XDR tools. We called them the “security refinery” of the modern era because they clean, enrich, and route raw telemetry into structured, high-quality data that analysts can actually use.
It also made an important point about why this market was growing so fast. Data growth, rising compliance demands, and tool sprawl were all putting pressure on SOCs to find a more efficient way to manage telemetry. The report highlighted that SDPPs not only reduce cost but also improve the quality of data, helping faster threat detection.
We also highlighted how SIEM was evolving. Instead of serving as a single, monolithic system, the modern SIEM is shifting toward a modular architecture that separates storage from analytics. This new model allows data to live in cheaper cloud storage while being queried on demand, giving organizations the flexibility to scale without breaking their budgets.
The report clearly anticipated the convergence between pipelines, data lakes, and SIEM systems. It painted a picture of a security data fabric where ingestion, storage, and analysis would become part of one unified layer. For many in the industry, that idea shifted the conversation away from which SIEM to buy toward how to build the data architecture that supports it.
In short, Security Data Pipeline Platforms are becoming a must-have for modern organizations because they completely change how security data is collected, processed, and used. Here’s a deep dive into why they matter and how they have now evolved to become the control plane for SOC.
Acquisitions: A Wave of Consolidation Across SDPP Vendors
Good security depends on good data. Because of this, SIEM and XDR vendors are moving quickly to control the pipelines that clean, shape, and route telemetry. This shift marks the beginning of a new phase in the market, where data quality becomes just as important as detection or response.
Over the past two years, several major security and observability companies have acquired smaller pipeline and telemetry vendors. This trend shows that the industry now understands how important the data pipeline has become. Modern security platforms need high quality, well prepared data before they can deliver strong analytics or AI driven outcomes. This growing importance is evident in the push from large vendors to bring pipeline technology in house instead of relying on third parties.
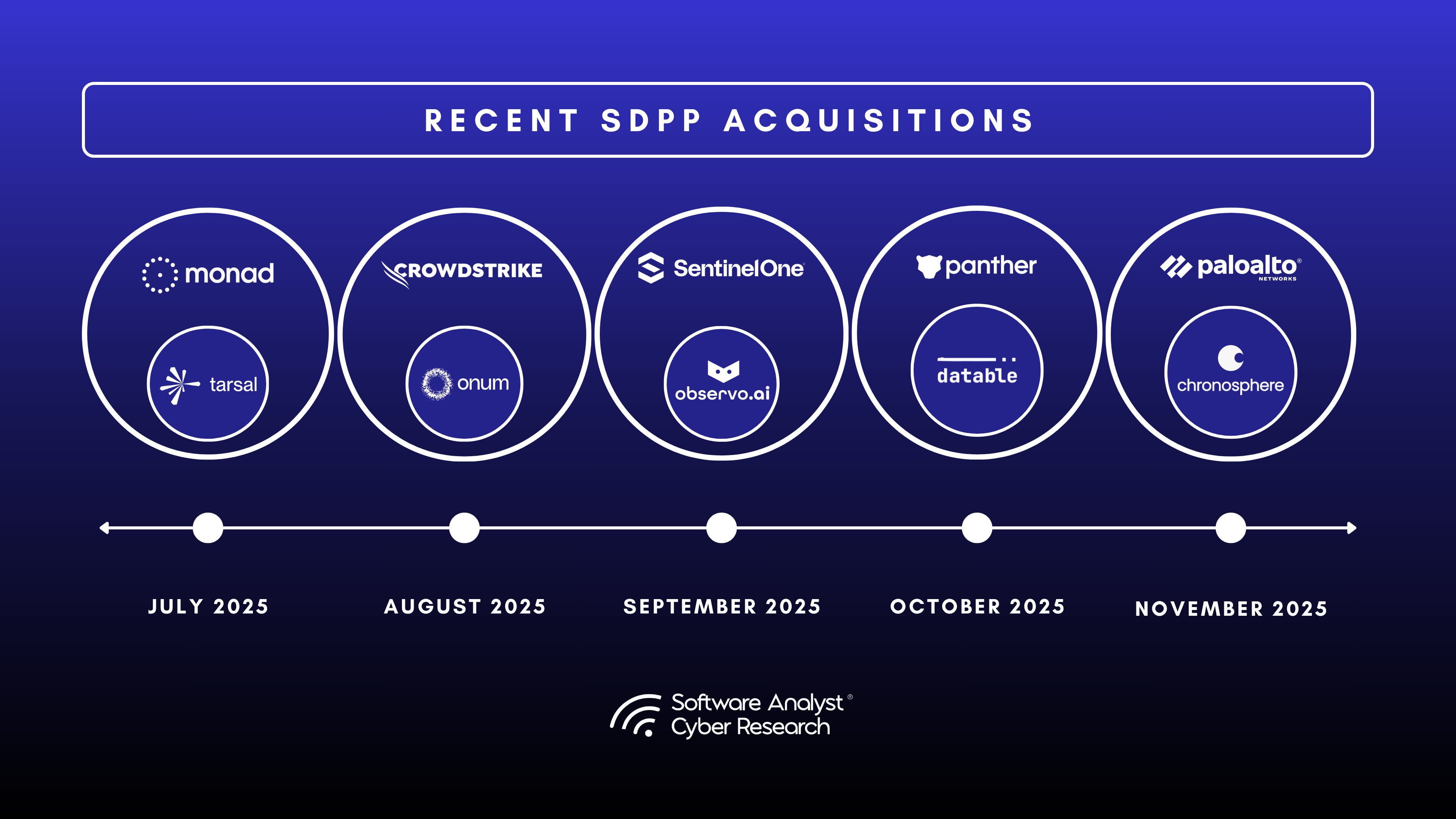
In chronological order of announcements –
- Tarsal: Tarsal was acquired by Monad to enhance its security operations and data management capabilities in July 2025 – one of the first acquisitions.
- Onum: CrowdStrike acquired Onum for about US$290 million.
- Observo AI: SentinelOne acquired Observo AI for approximately US$225 million (cash + stock) to enhance its data-pipeline/SIEM capabilities.
- Datable: Panther Labs announced acquiring Datable, a security-data-pipeline platform. (Amount undisclosed)
- Chronosphere: Palo Alto Networks announced acquisition of Chronosphere, a major observability platform with pipeline capabilities for $3.3B dollars, on November 19, 2025.
What Acquisitions Mean for Broader Security Platforms
These acquisitions show a clear trend: Security Data Pipelines are becoming the control plane of modern security operations. Vendors want to sit closer to the source of data because strong AI and strong analytics depend on clean, well-structured telemetry. Instead of competing on dashboards or detection content, companies now compete on data quality, consistency, and readiness.
This shift brings clear benefits for customers of the broader platforms – the SIEMs. Performance improves, noise decreases, and storage costs go down. The core message is simple. Whoever owns the data quality and routing, has a larger play in the modern, decoupled, SOC architecture. And hence, the pipeline layer is becoming the heart of the SOC and the operational place where teams decide what data matters, how it should be shaped, and where it should go. It governs data quality, routing, enrichment, and lifecycle management, shaping how downstream tools perform.The platforms that integrate natively with Security Data Pipeline platforms will define the next generation of modern analytics platforms.
These acquisitions confirm that the future of SIEM, XDR, and AI SOC technologies will rely on a strong, unified control plane built in the pipeline layer. Whoever controls this layer ultimately controls the quality, cost, and intelligence of the entire SOC stack.
Neutrality Concerns with Acquisitions
Although the acquisition strengthens the larger platforms, it raises concerns about neutrality for users of the security data pipeline platforms.
As more SDPP vendors are acquired by large SIEM, XDR, and observability platforms, security leaders are beginning to express clear concerns. The biggest worry is the potential loss of neutrality. Many organizations adopted independent pipeline platforms because they provided flexibility, transparent routing, and the freedom to choose or change destinations without friction. When these platforms become part of a larger ecosystem, their priorities may shift toward favoring the parent vendor’s integrations while downplaying independent capabilities. This can limit multi-destination routing, reduce portability, and recreate the very vendor lock-in that SDPPs were designed to eliminate.
There is also apprehension that innovation in the category may slow as acquired platforms are folded into broader product roadmaps. Independent SDPPs often moved quickly, responding directly to practitioner needs. Once inside a major vendor, development may be shaped by platform alignment rather than customer choice. For now, many of the acquired companies have shared that their vision is to continue supporting the standalone security data pipeline platform to its users without forcing lock-in. Whether this trend will continue to evolve, is to be determined.
The Evolution of Security Data Pipeline Platforms as a Distinct Category
Pipeline capabilities are sometimes merged into broader platforms such as SIEMs, observability tools, or XDRs. However, the focus of this report is primarily on what we refer to as “pure play” security data pipeline platforms.
Pure Play Security Data Pipeline Platforms
These platforms focus primarily on the data transformation layer between data sources and data destinations. We will see in the latter parts of the report, a trend where these platforms envision to take more of the adjacent capabilities gradually, we call that “SDP PLUS”, but in their current state, they still heavily fall under “Pure play” Security Data Pipeline Platforms.
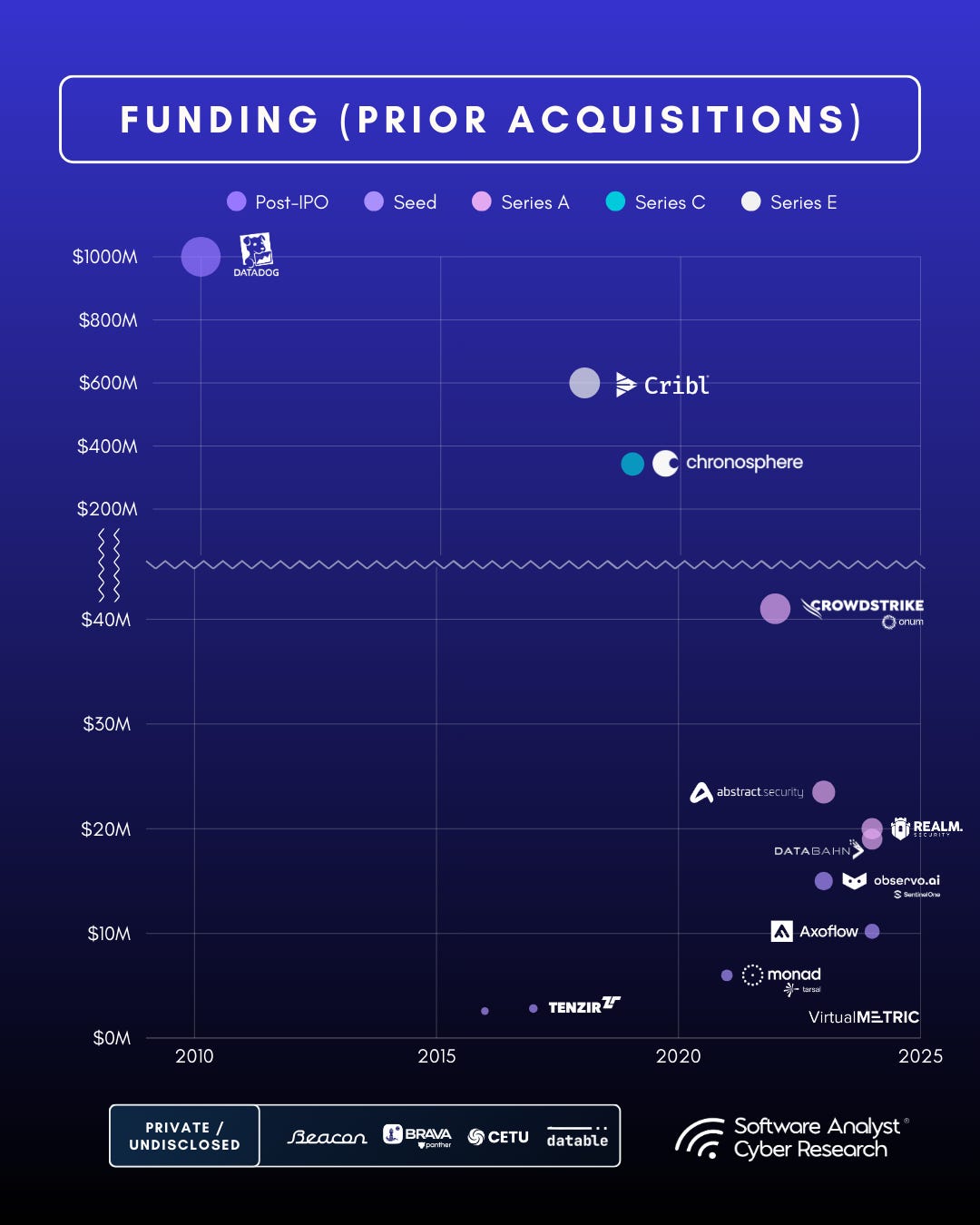
Cribl (2018) stands as dominant Series E player with funding above $600M, and at $3.5B evaluation, embodying a broader shift from log routing to full security data pipeline platform. Cribl still stands at the center of the Security Data Pipeline Platform (SDPP) market as its most mature and influential leader both technically and commercially. Many of the practitioners we interviewed know the SDP market by Cribl’s name.
Emerging Entrants
In addition to Cribl, we’ve done an in-depth analysis of these emerging security data pipeline platforms in this report. In Alphabetical Order –
- Abstract Security founded in 2023, raised $15M dollars in Series A in 2024.
- Axoflow founded in 2023, seed round of $7M dollars in Jan, 2025.
- Beacon Security came out of Stealth in November, 2025.
- Brava Security – currently in stealth
- CeTu founded in 2024
- Databahn in 2023, $17M dollars in series A, in Jan 2025
- Datadog launches Observability Pipelines – June 2022
- Datable founded in 2023
- Onum founded in 2022, acquired by Crowdstrike
- Observo AI in 2022, acquired by SentinelOne
- Tenzir, founded in 2017, raised $3.3M dollars in seed round
- Realm Security founded in 2024, raised $15M in series A
- VirtualMetric, founded in 2025, raised $2.59M in seed round
While early infrastructure players consolidated around observability and log management, the platforms are now focusing on security and attacking specific SOC pain points: data quality for security, ingestion cost, AI normalization, and cross-platform routing.
Growing Investment in the Security Data Pipeline Category
Insights
- The average jump from Seed to Series A/D rounds across these vendors ranges from 4x to 10x in valuation, signaling strong investor confidence in SDPP platforms.
- Consolidation is accelerating : Observo AI, Datable, and Onum were acquired by major security players (SentinelOne, Panther Labs, and CrowdStrike).
- Palo Alto Networks announces acquisition of Chronosphere for $3.3B on Nov 19, 2025 .
Over the next three years, we anticipate capital will continue moving toward pipeline-driven ecosystems that combine telemetry management, AI readiness, and cost efficiency, forming the backbone of the next security data economy.
Security Leaders Voice
Now that we’ve recapped what happened during our last research, it’s time to mention what we learned these past months from many practitioner calls, security vendor in-depth interviews and product briefing and a questionnaire that covered every single detail of platform capabilities.
Security data pipelines began as a cost-saving broker. But they are now strategic policy engines for visibility, control, and agility. The practitioners adopting these platforms are not chasing hype around autonomous SOCs. They are building disciplined, deterministic systems supported by selective automation. The future of detection will belong to teams that control their data with the same rigor they apply to threat response and SDPPs are becoming an important layer that make this possible. Data control is the new detection.
Across industries, from financial institutions to managed service providers and industrial operations, the message is consistent. Security data pipelines are no longer considered back-end utilities. They are becoming the operational control plane for telemetry, cost management, and detection agility.
Practitioners entered this space to reduce log costs, but they stayed because of control. By centralizing routing, transformation, and lifecycle management, the pipeline has shifted from infrastructure to intelligence. One leader summarized it plainly: “We are not just compressing data anymore. We are deciding what matters and where it should live.”
These conversations show a shift from tool-centric thinking to outcome-centric design. Practitioners prioritize three things above all:
- The ability to reduce data ingestion at SIEMs and automatically express transformations
- Multi-tier intelligent routing that aligns storage cost with data purpose
- Built-in observability that measures ingestion completeness and source health
Ease of management is becoming a key differentiator. Teams managing multiple customer environments (MSSPs) prefer centralized templates where one pipeline update can propagate across tenants. Smaller organizations prioritize alignment with their deployment style, especially infrastructure-as-code.
Expanding on these use cases, we asked practitioners to stack rank SDPP capabilities. And here’s what we found –
Budget Management as an Entry Point
The original motivation was budget pressure and it remains one of the biggest reasons. Teams set reduction goals without losing context, cutting ingestion volume while improving fidelity. One leader cited processing over three terabytes of daily data but forwarding less than half of that after filtering. The immediate benefit from SDP platforms is lower cost at destination, but the deeper change is operational freedom. In the words of one leader, “You cannot automate nonsense.” Poor data quality is still the most expensive problem in the SOC.
Normalization is the New Norm
Every practitioner began their modernization story with data normalization. They view consistent schemas as the precondition for any mature detection or analytics program. When normalization is right at the start, vendor content and correlation logic across the stack finally work as designed.
Intelligent Pipelines
Modern designs favor data adjacency rather than consolidation. Practitioners anticipate and prefer Pipeline platforms to adopt AI capabilities or intelligent routing with an understanding of data to direct data to the most cost-effective and policy-compliant storage, whether local, cloud, or cold archival, without binding analysis to a single ecosystem. These leaders want to govern the full data lifecycle, deciding what stays hot, what rolls warm, and what archives cold with clear rehydration paths when investigations begin.
Noise is not the enemy, silence is
A recurring theme across interviews was the danger of quiet systems. Practitioners worry more about missing telemetry than excessive alerts. They described the problem of dormant integrations, acquisitions without visibility, and logs that silently stop forwarding. The emerging use case is “silence detection,” where the pipeline monitors the health of every data source and flags anomalies in activity levels or schema freshness.
AI is Becoming Familiar
Industry is becoming more and more comfortable now with the idea of agentic AI or copilot capabilities, however, not really buying the “autonomous” messaging yet. Leaders emphasized they are not ready to hand decisions to autonomous agents. They do, however, welcome targeted automation that eliminates repetitive work. They want AI to generate parsers when formats change, to detect version drift, to cluster similar events, and to perform quality assurance on closed investigations. They want explainable automation, not invisible reasoning. The ideal is agentic assistance, not autonomous control – yet.
Shifting Detections Left, into the Stream
The idea behind this direction that a few security data pipeline platforms are indulging in, is to detect threats based on IOCs while data is streaming through your security data pipeline. By moving detections into the stream and closer to the pipeline, you bring detection logic closer to the source and avoid the post-index costs or latencies that occur at SIEM destinations. This results in faster threat detection and reduces MTTD with near real-time speed.
While the concept in theory sounds impressive, in our interviews with practitioners, it received mixed feedback. Some welcomed the visibility into threat earlier in the stream, but some suggested they didn’t see speed of detection in stream as their priority when speed of remediation is yet to catch up. Among those who saw value, organizations are experimenting with lightweight detection logic in stream, with an aim to add more context to the data that is routed to destinations. The goal is not to replace centralized analytics but to reduce dwell time and stage response earlier. Several teams already use the pipeline to automatically collect forensics when certain triggers appear, with detection in stream, the idea is to now surface these triggers without post-index delays saving time on detection and latency.
Acquisitions and the Question of Losing Neutrality
Early adopters embraced SDPs because they sat between systems and provided architectural control, flexibility, and cost savings without locking the customer into a single platform. That neutrality was the differentiator. Now, as major SIEM and data infrastructure players acquire pipeline companies or replicate their features, the market risks returning to the very vendor dependency that SDPs were meant to eliminate.
In the practitioner’s words, “we’re just going to end up back where we started, everything re-bundled under one large platform.” The most valuable providers will integrate broadly across SIEM, observability, and data lake layers while keeping control in the hands of practitioners. The differentiator will not be who owns the data, but who enables transparent, vendor-agnostic flow across it.
If pipeline vendors continue to prioritize openness and integration, they can remain the connective tissue of modern security architectures. If they instead chase full-stack ownership, they risk becoming another feature in someone else’s platform.
The Pipeline Becomes the Control Plane
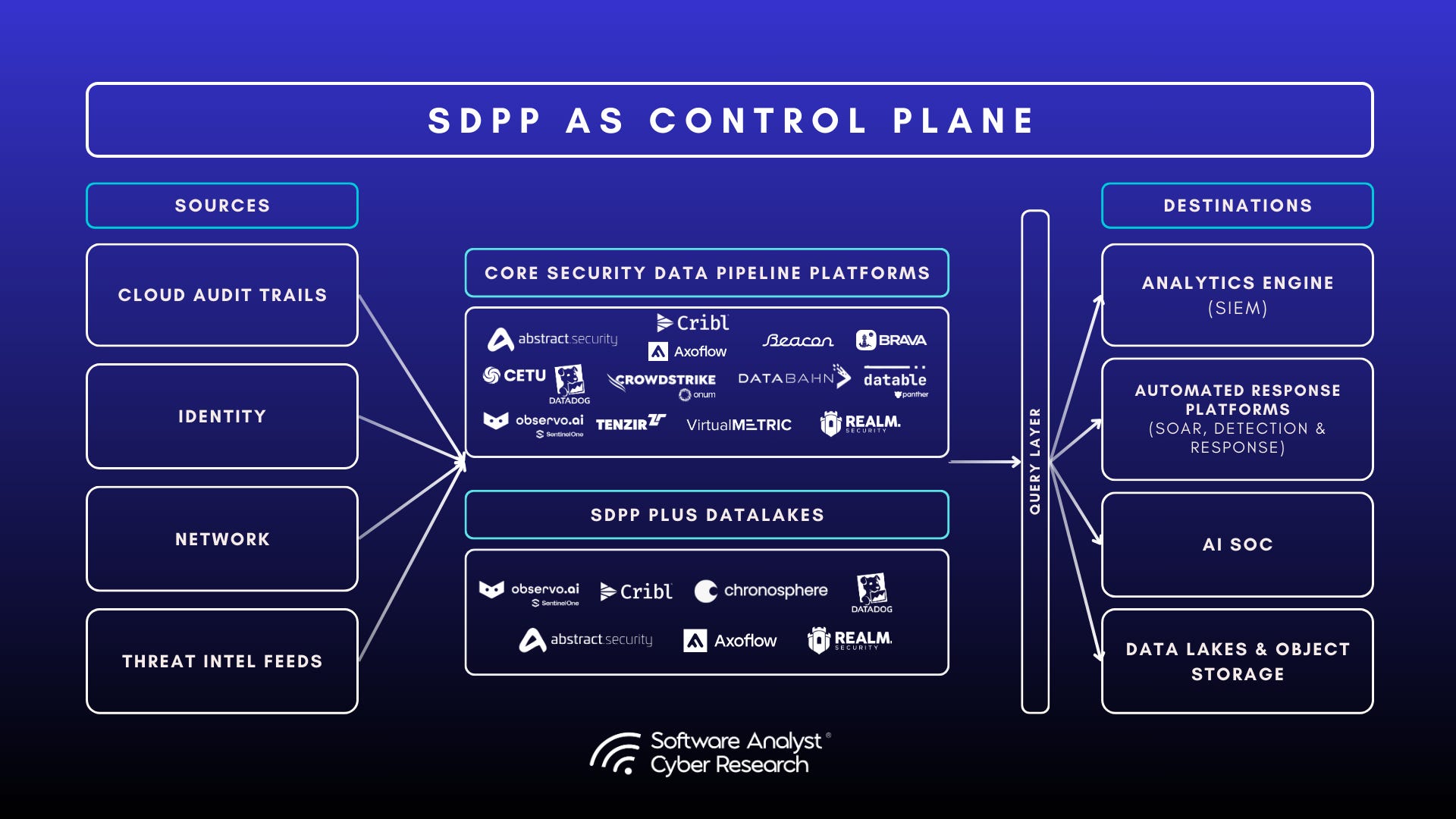
Security data pipelines are often misunderstood as ETL for security, simple brokers that route data from point A to point B. But modern platforms deliver far more. They are becoming the control plane for how security teams manage, govern, and trust their telemetry across SIEM, detection, response, AI, observability and long-term analytics.
Security leaders today face rising data volumes, constant schema changes, noisy logs, silent data dropouts, inconsistent enrichments and mounting SIEM and data lake costs. Traditional ingestion or basic filtering cannot keep up. What is emerging is a new class of platforms designed specifically for security data. These platforms reduce noise without losing security context, normalize and enrich at scale, auto generate parsers, detect schema drift, monitor data source health including silent failures and apply AI to make the pipeline self optimizing.
Across the industry, what is clear is this: Security data pipeline platforms are moving from helpful optimization to the foundational control layer of the SOC architecture. They sit at the center of the architecture and shape how every downstream tool performs.
Below is a concise breakdown of the key capabilities these platforms bring and the innovations security leaders should watch as the category evolves.
Readers Note: Some of the features mentioned in the section below may only be offered by more advanced security data pipeline platforms. In the vendor section, you will find a detailed description and an in-depth evaluation that makes it easier for security leaders to compare and understand what each platform provides.
Core Pipeline Capabilities
Core pipeline capabilities across most security data pipeline platforms include the following
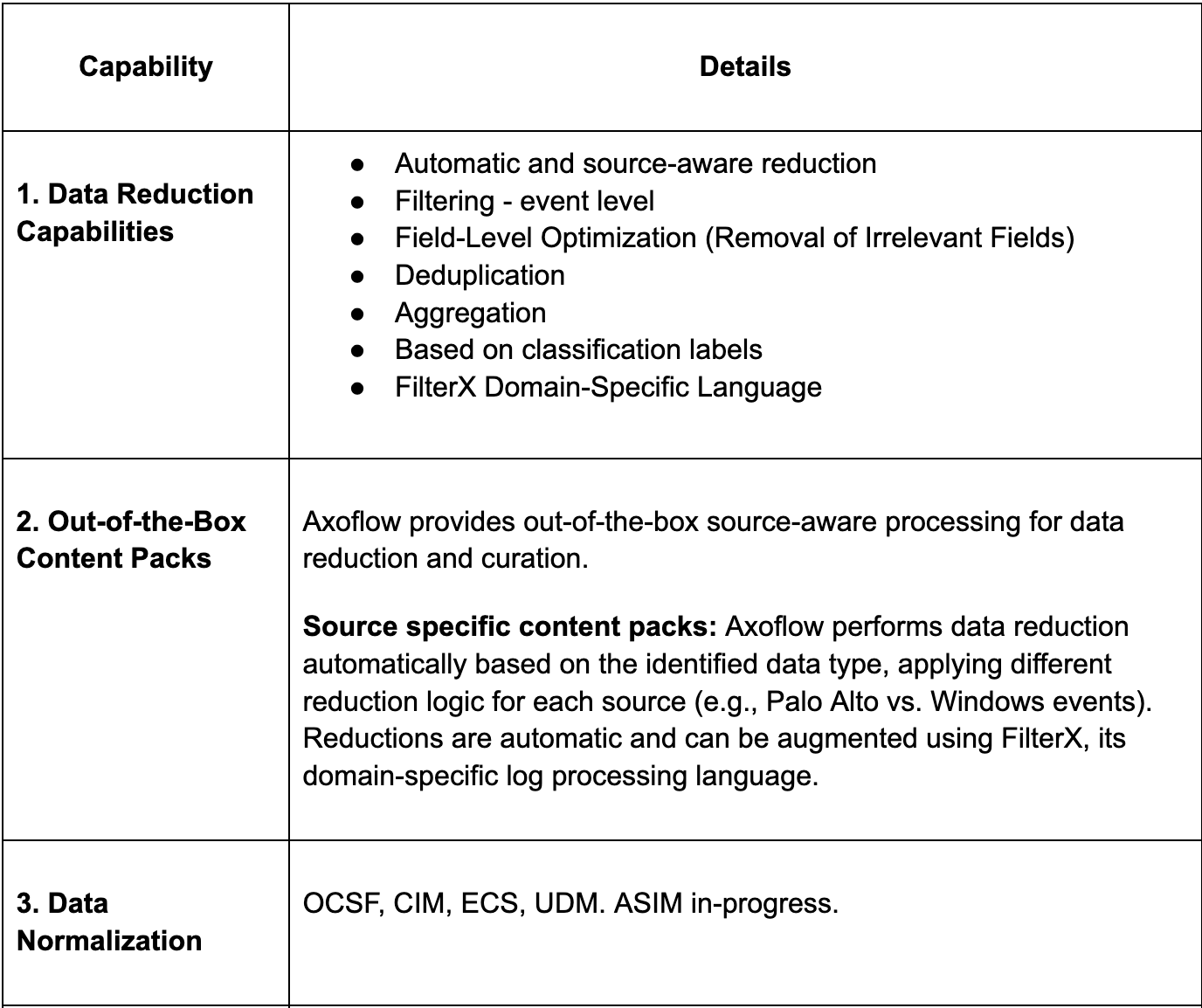
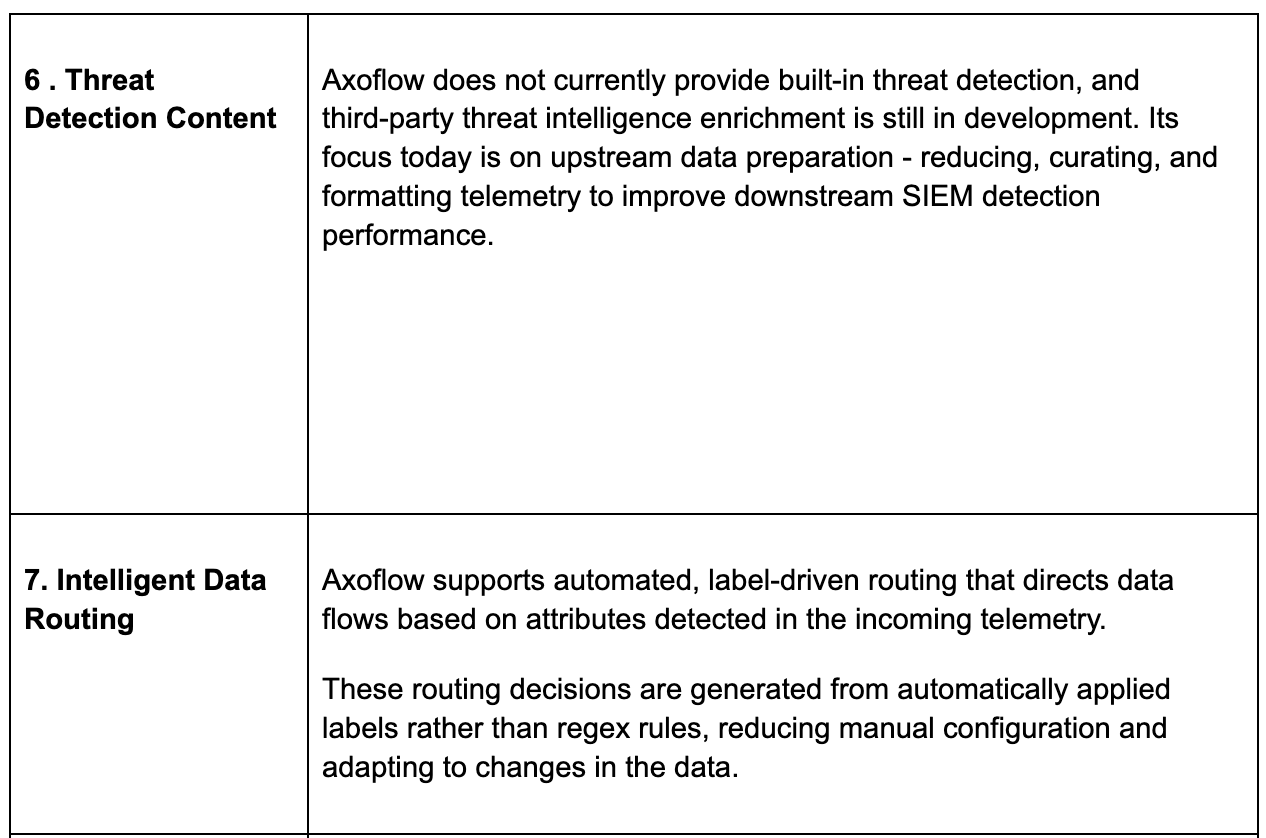
Advanced Data Reduction Beyond Simple Filtering
Data reduction is not just about shrinking data volume. In security, it means preserving investigative value while eliminating noise and unnecessary cost. This section covers how modern pipelines intelligently reduce data without weakening detection fidelity.
Early pipeline wins came from cost savings, but reduction has become much more intelligent than dropping fields.
What SDPPs can actually do
- Context aware suppression that removes duplicates or repetitive events while preserving indicators and security context
- Conditional reduction at both field and event level
- Adaptive sampling that dynamically adjusts sampling rates based on peak ingestion times
- Payload trimming that removes non security relevant metadata like verbose debug fields or oversized payloads that add cost but not value
- Schema aware reduction that preserves detection relevant fields while trimming high volume noise
- Summarization and metricization that convert chatty logs into compact metrics without losing investigative value
- Priority based reduction that adjusts logic by log type
- Real time shape correction that transforms data in proper formats before they hit downstream systems
Together, these techniques ensure data reduction is cost efficient and security aware rather than blind trimming.
Emerging Innovations
- Dynamic reduction tuned by threat context or incident state
- AI assisted reduction recommendations based on historical alerting patterns
- User configurable reduction tiers aligned to detection criticality
- Automated validation to ensure reductions never strip fields needed for investigations
Why it matters
Security teams reduce SIEM spend while keeping the fidelity needed for investigations. Leaders repeatedly said they want tools that help them do more with less without degrading security.
Normalization and Schema Discipline
Normalization ensures that every log source speaks a consistent language. This allows detections, analytics, and investigations to work reliably across diverse destination systems. Schema discipline prevents breakage and enables large scale correlation.
Nearly every practitioner called this the top priority.
What SDPPs can provide
- Automatic normalization into standards such as OCSF, ECS, UDM or custom schemas
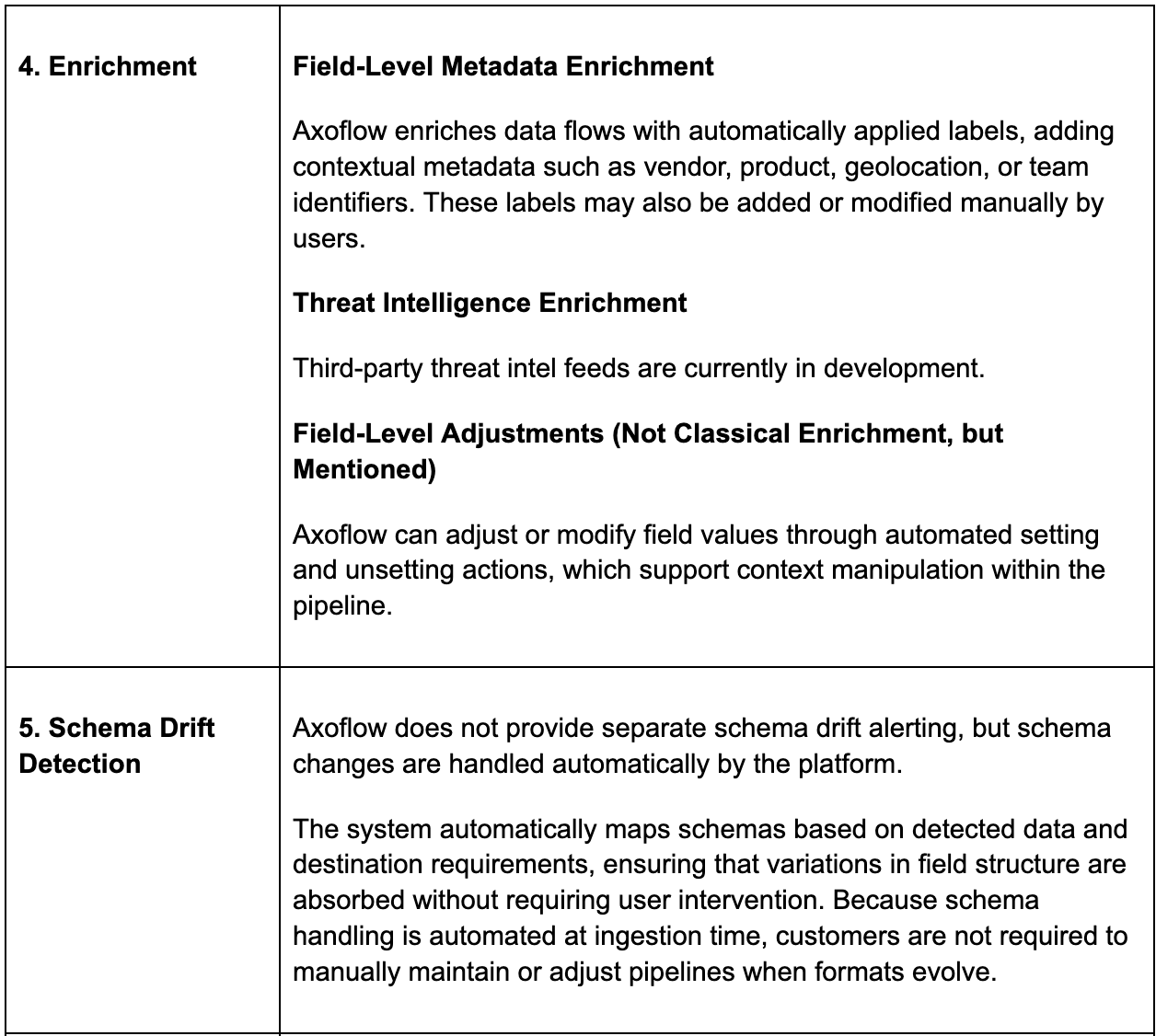
- Schema drift detection when a data source silently changes formats
- Automatic parser creation using AI for new versions and undocumented logs
- Consistent field naming across all data sources to unlock SIEM content and correlation
Emerging innovations
- AI generated parsers based on sample logs and intended destination schema
- Automated detection of unexpected new fields or missing required fields
- Version aware normalization that adapts when vendor log formats update
- Normalization confidence scoring to flag risky transformations
Why it matters
If data does not show up clean and consistent, SIEM, XDR, SOAR, UEBA, AI SOC and detections all suffer. Good data unlocks the entire detection library.
Contextual and Threat Intel Enrichments
Raw logs lack the context analysts need. Enrichment adds meaning, giving logs identity, asset and threat relevance so alerts and queries become more accurate and actionable.
SDP platforms act as enrichment hubs, adding rich context in stream, to strengthen analysis at destination.
Examples
- Environmental context such as GeoIp, cloud account or region
- Identity context such as user, department and privilege level
- Asset context including owner, business app and criticality
- Threat intel matches for IPs, domains and hashes
Emerging innovations
- Pre enrichment policies that vary based on log type or threat level
- Inline lookup optimization for high speed enrichment
- Automated asset tagging based on behavioral patterns
- Dynamic enrichment paths that enrich only when detection relevance is high
Why it matters
Enrichment turns raw events into signals analysts can act on. By adding context such as identity, asset and threat context in the pipeline, teams reduce triage time, improve correlation quality and make AI driven use cases more reliable without adding extra steps later.
Intelligent Routing and Multi Tier Storage Control
Not all data should be treated equally. Intelligent routing ensures each log is sent to the right place at the right cost tier while maintaining flexibility across SIEMs, data lakes, and analytics tools.
This is where the pipeline becomes the control plane.
What SDP Platforms provide
- Route hot, warm and cold based on log value
- Split streams to multiple SIEMs, detection tools or cloud lakes
- Apply different reduction schemas by destination
Emerging innovations
- Price aware routing where users can split pipeline routes to choose storage based on cost differences across cloud providers
- Vendor agnostic SIEM migration paths
Why it matters
Routing and storage decisions directly drive cost, performance and flexibility. Intelligent routing lets security teams control where data lives, keep hot paths fast for investigation and avoid being locked into a single SIEM or storage vendor.
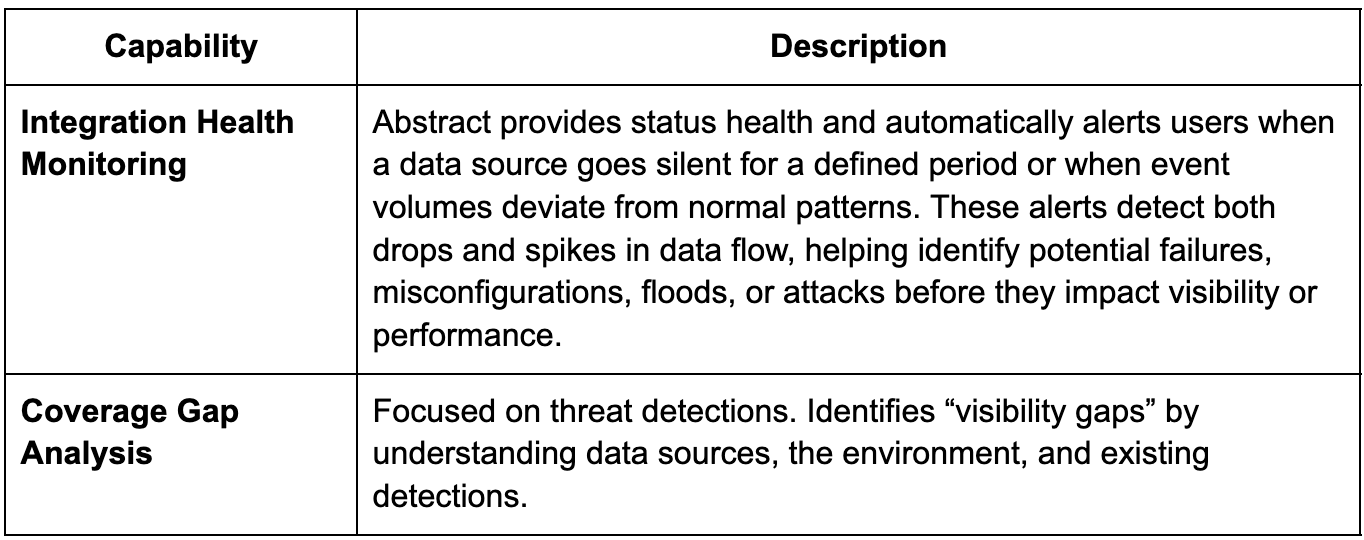
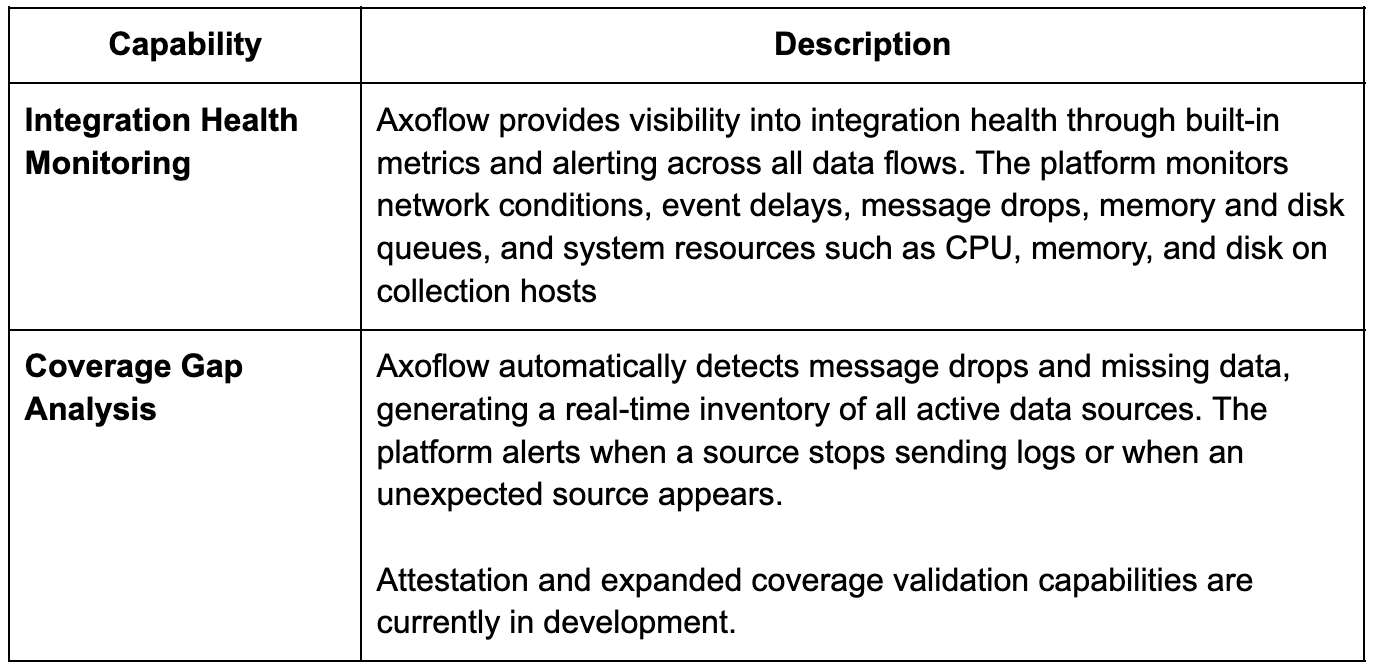
Intelligent Integration Health Monitoring
Noise is not the only enemy, sometimes silence is a bigger threat. Security teams need to know not just what is happening, but whether critical telemetry is flowing at all times. Monitoring for noise, errors and silent dropouts ensures visibility gaps do not turn into undetected incidents.
What SDP Platforms provide
- Detect silent quitting of sources – Integration health at source level
- Monitor ingested volume against historical baselines
- Alert on pipeline stalls or destination issues
Innovations to note
- Automatic discovery of newly active or inactive sources
- Health scoring of each data source over time
- Behavioral baselines for normal telemetry flow
- Automated response actions when a source goes dark
- Detect sudden drops in fields or event types
Why it matters
If critical sources go dark or degrade, SOC metrics may still look healthy while real blind spots grow. Source and pipeline health monitoring makes telemetry reliability visible so teams can trust their coverage claims and respond quickly to gaps.
AI Assisted Pipelines
AI brings speed and automation to pipeline tasks that were historically slow, manual and error prone. Practitioners are now growingly comfortable with the idea of AI use within pipeline platforms, The high value application of AI on pipeline platforms is not to be compared as similar to autonomous SOC claims. Instead of replacing analysts, AI in the pipeline reduces operational burden by providing pipeline recommendations, accelerates onboarding of new data sources and strengthens data quality before detections even begin.
AI directly addresses several long standing pain points. First, onboarding new log sources is too slow, especially during platform migrations or when connecting new environments. Security leaders noted that the speed at which they can ingest and normalize data determines how quickly they can address issues at destination platforms like SIEMs. AI generated parsers and automated normalization drastically shorten the time from raw logs to usable telemetry.
Second, many leaders stressed that high alert volume is often not due to weak SOC workflows but because prerequisite work in data quality, clustering and correlation is incomplete. AI in the pipeline helps reduce this noise by automatically grouping related events, generating cleaner schemas and ensuring that logs arrive enriched and structured, which lowers the alert queue burden downstream.
Third, teams repeatedly warned about silent failures in telemetry. AI powered baselining and anomaly detection on data flow can identify when sources go dark, when formats drift or when volumes shift abnormally, addressing a critical visibility gap.
Early innovations
- AI generated parsers
- AI driven pipeline creation
- Automated anomaly detection in transit
- Semantic classification of log types
Innovations to note
- Recommendations for pipeline optimization
- AI analysis that validate schema drift and transformation status
- Predictive detection of missing log integrations
- Automated rerouting when pipeline detects destination health failures
Why it matters
AI assisted pipelines absorb repetitive engineering work and constant change in vendor formats. That frees scarce security engineers and analysts to focus on detections, investigations and architecture rather than plumbing.
Unified Security Data Control Plane
As capabilities converge, security pipelines are becoming the strategic control layer that governs how telemetry is shaped, enriched and used across the entire SecOps stack.
What it provides
- Central governance of data quality
- One place to enforce schema, reduction and routing policy
- A foundation for consistent AI and analytics
- Control plane APIs for external orchestration
- Policy as code for data governance
- Unified dashboards showing security, cost and performance impacts
- Automated end to end lineage tracking for every event
Why it matters
Treating the pipeline as a unified control plane gives CISOs one place to govern data quality, cost and access. This foundation makes it easier to evolve tools, adopt new analytics and AI, and respond to regulatory or business changes without constantly reworking integrations.
When reduction, normalization, enrichment, schema governance, routing, data health and AI automation converge, pipelines become the central control plane for deciding how telemetry is used in end systems.
Recent acquisitions show that SIEM vendors understand this. The pipeline is the strategic chokepoint. Whoever controls the data layer influences the entire SOC stack.
Emerging Trends
Here are some emerging trends we see across some of these modern security data pipeline platforms –
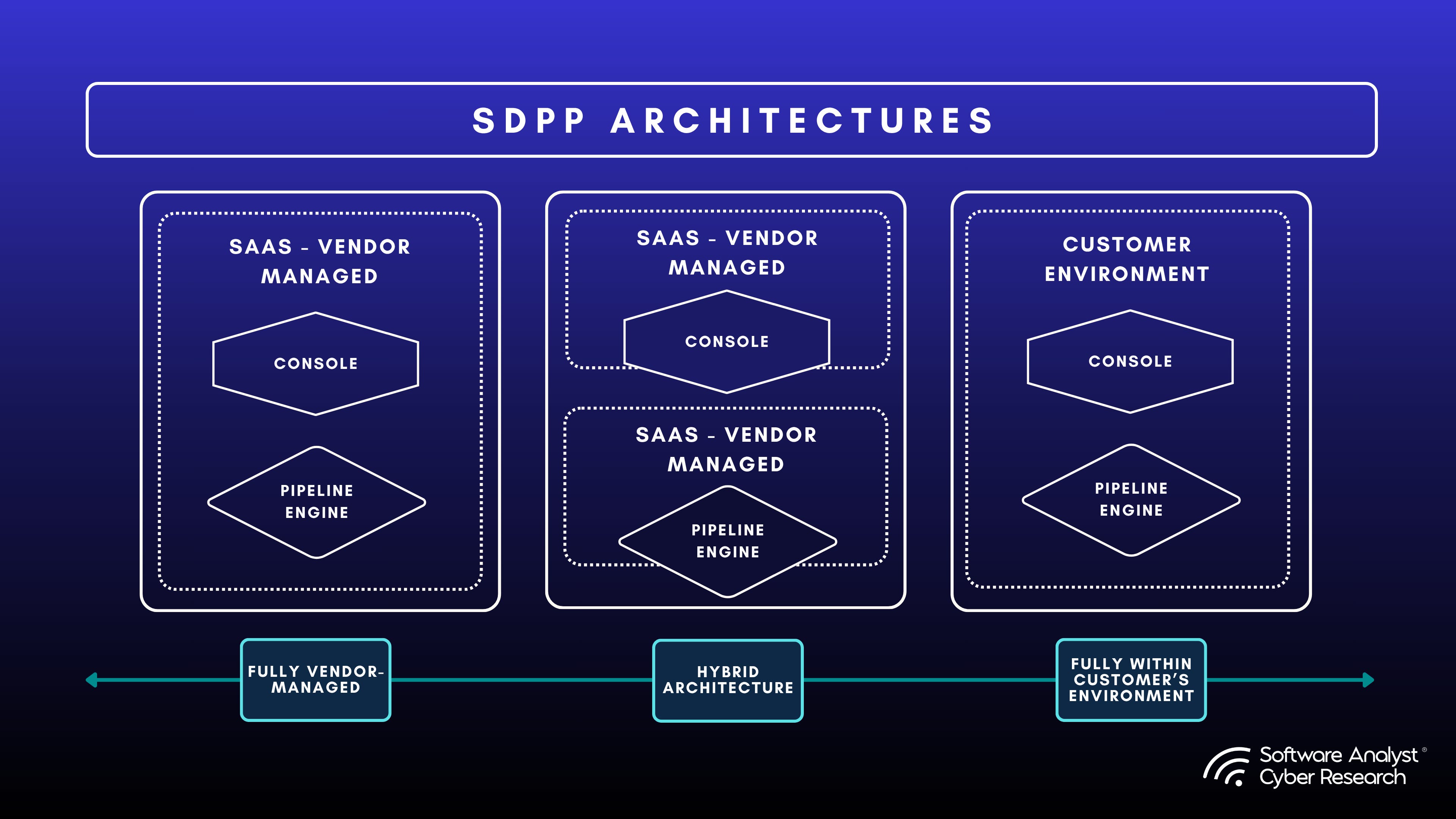
Deployment and Distribution Flexibility
We see these platforms offering flexible deployment options, typically using a split model with a Control Plane and a Pipeline Engine. Many of these vendors also offer multi-tenancy to support MSSPs and large enterprises.
Advanced Normalization, Enrichment, and Context Fabric
Normalization and enrichment are becoming richer and more automated across vendors. Abstract normalizes into multiple schemas, enriches with identity, asset, vulnerability, and threat intel, and auto-corrects drift with ASE. Databahn transforms data into CIM, OCSF, UDM, ASIM, LEEF, and more using AI while enriching with STIX/TAXII threat intel. Axoflow auto-classifies logs, applies schema mapping, and enriches with metadata. Beacon aligns to ECS, OCSF, CIM, and UDM while combining cross-source context through Recipes. CeTu provides AI-assisted normalization with lookup enrichment and threat intel overlays. Brava enriches telemetry with attack-simulation context, relevancy scoring, and MITRE mappings. Cribl enriches data through lookups, Redis, GeoIP, and DNS, with schema drift detection forthcoming.
Intelligent Routing and Multi-Destination Control
Routing decisions are becoming value-based and policy-aware across vendors. Abstract recommends routing based on detection value and cost. Axoflow uses classification labels to drive automated routing. Beacon’s AI-guided posture directs logs to SIEM, data lakes, or cold storage based on importance. CeTu’s Zoe assistant selects routes tied to analytic relevance, cost, and detection needs. Databahn’s Cruz AI evaluates query patterns and detection impact to recommend tiering and routing paths. Brava routes high-efficacy logs forward while summarizing or filtering low-value data. Cribl Stream provides granular routing from any source to any destination, using Copilot to generate logic from plain language.
Integration Health and Coverage Insights
Vendors now offer deep insight into data coverage, stability, and silent failures. Abstract detects silent dropout, schema drift, and volume anomalies with automated parser correction. Beacon’s Logging Posture highlights missing telemetry and coverage gaps using its Collectopedia knowledge base. Databahn scores source health based on quality, completeness, drift, and destination stability. Axoflow alerts on missing sources, unexpected new sources, and message drops. Brava maps coverage gaps using attack simulation aligned to MITRE techniques. CeTu VISION analyzes SIEM coverage and highlights blind spots across environments. Cribl Insights surfaces backpressure, drops, latency, and health issues across Stream, Edge, and Lake deployments.
AI-Assisted Pipeline Management
AI is maturing into a core operational layer in nearly all vendors. Databahn emerged as a leader in their AI capabilities and maturity. Abstract’s ASE generates parsers, manages drift, builds pipelines, and enriches detections. Axoflow uses supervised AI for classification, schema mapping, and natural-language pipeline creation. Databahn’s Cruz automates parser generation, correction, routing intelligence, and ecosystem-specific model transformations. Cribl’s Copilot assists with schema mapping, routing logic, and query generation. Beacon applies agentic reasoning to Recipes, posture, schema mapping, and normalization. CeTu’s Zoe and DEPTH engines power routing decisions, drift detection, and pattern intelligence. Brava uses AI to evaluate telemetry efficacy through attack simulations and relevancy scoring tied to detection strength.
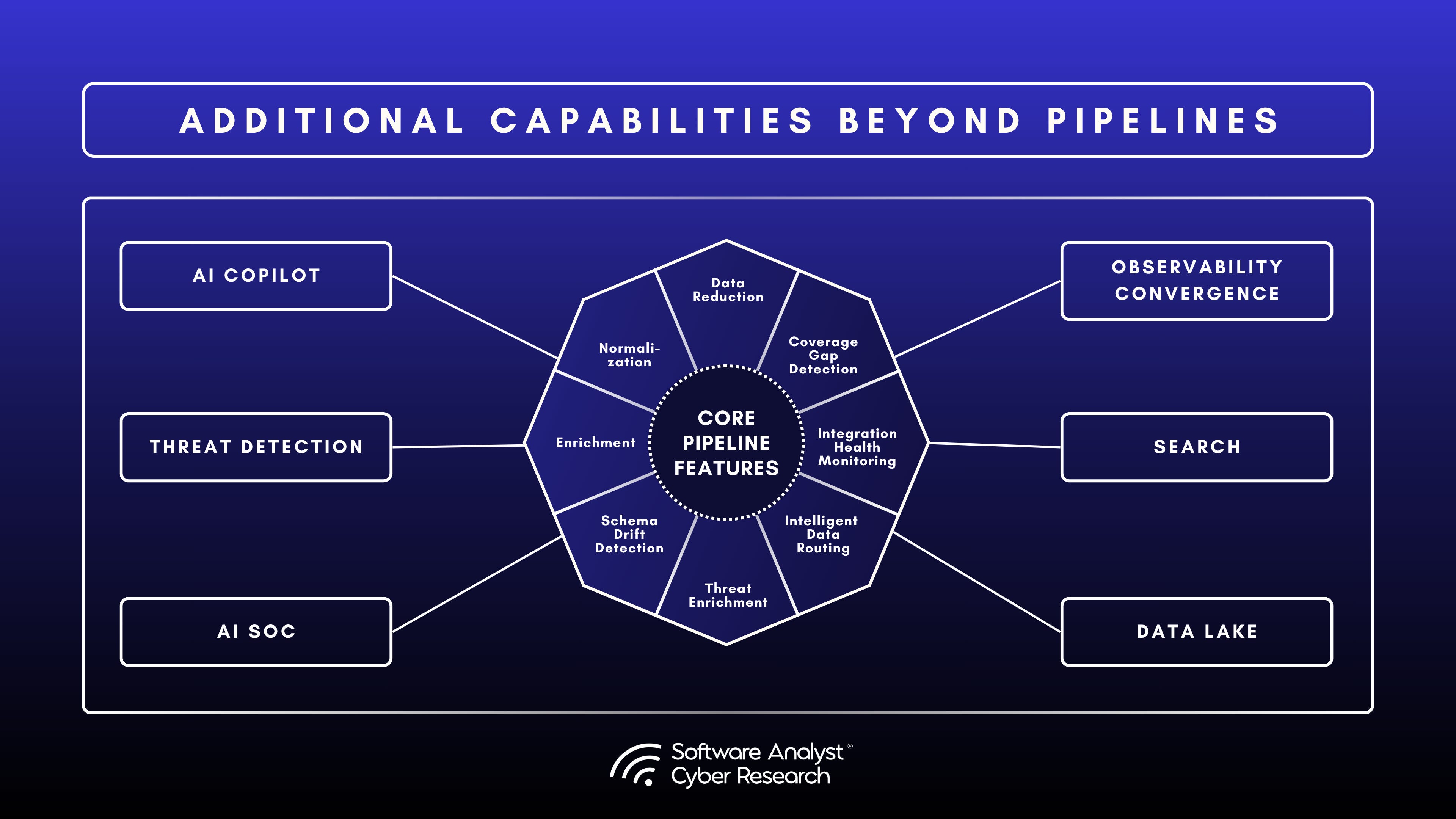
SDP PLUS Platforms
In addition to core pipeline features, we are seeing an emerging trend where pure-play SDP platforms are envisioned to expand beyond traditional pipeline capabilities. These include in-house data lake option with tiered storage, AI assisted capabilities, threat detections and analytics in the pipeline layer, federated searches and querying across SIEMs and Datalakes, Observability convergence and AI SOC like capabilities. Here are some of the features we saw among the vendors we analyzed.
Data Lakes and Tiered Storage
Vendors increasingly offer storage and replay layers that extend pipelines into long-term retention. Abstract provides Lake Villa with hot, warm, and cold tiers and real-time querying. Cribl offers Cribl Lake and Lakehouse for open-format retention and fast access to recent data. Axoflow includes AxoStore, AxoLocker, and AxoLake as part of its multi-layer storage design. Databahn offers optional tiered lake storage for customers needing centralized history. Brava supports seamless retrieval from low-cost storage directly through the SIEM. CeTu does not mandate a lake but provides a unified architecture that can route to object stores or archival platforms. Beacon avoids owning storage but enables routing to cold tiers across customer-controlled buckets.
Search, Querying, and Federated Visibility
Search and query capabilities are expanding directly from the pipeline layer. Cribl Search enables search-in-place across S3, Edge, Lake, and external object stores. CeTu offers cross-system querying that works across SIEMs and data lakes without a query language. Brava embeds natural language querying within the SIEM and retrieves cold data transparently. Databahn supports micro-indexing for rapid search across raw pipelines. Abstract allows real-time queries over normalized data through Lake Villa. Axoflow’s debugging and inspection tools show raw and parsed data side-by-side to support source comprehension. Beacon provides transformation previews and exploratory data analysis to validate pipeline accuracy.
Shifting Detections to the Stream
Threat detection in stream represents a shift toward identifying malicious activity as data flows through the pipeline rather than after it lands in a SIEM or data lake. The idea is to evaluate events in real time, applying lightweight correlation, IOC checks, and contextual signals before logs are indexed, which can reduce dwell time and provide earlier visibility into suspicious behavior. This approach also allows detections to carry enriched context downstream, improving the quality of alerts and investigations. While teams appreciate the speed and proximity to the source, most see in-stream detection not as a replacement for SIEM analytics but as a complementary layer that helps surface high-value signals, reduce noise, and begin the investigative process earlier. Vendors such as Abstract Security, VirtualMetric, acquired pipeline platforms and Tenzir already offer some threat detection capabilities. Realm Security is another entrant that plans to add this to its roadmap in the near future.
Evaluation Framework
Security data pipeline platforms deliver lower SIEM and storage costs at the minimum, but they also provide higher detection quality, better data governance, faster investigations, safer AI adoption, more resilient telemetry and freedom from vendor lock-in.
Most importantly, they shift teams from reactive ingestion problems to proactive control of the entire data lifecycle. They are not a sidecar tool. They are becoming the backbone of modern SecOps architecture.
In order to evaluate these vendors in depth, we conducted several deep-dive platform demos, used detailed questionnaires with linked evidence and screenshots to validate responses, and interviewed their customers to confirm our findings. Here are the broader categories under which the vendors were evaluated:
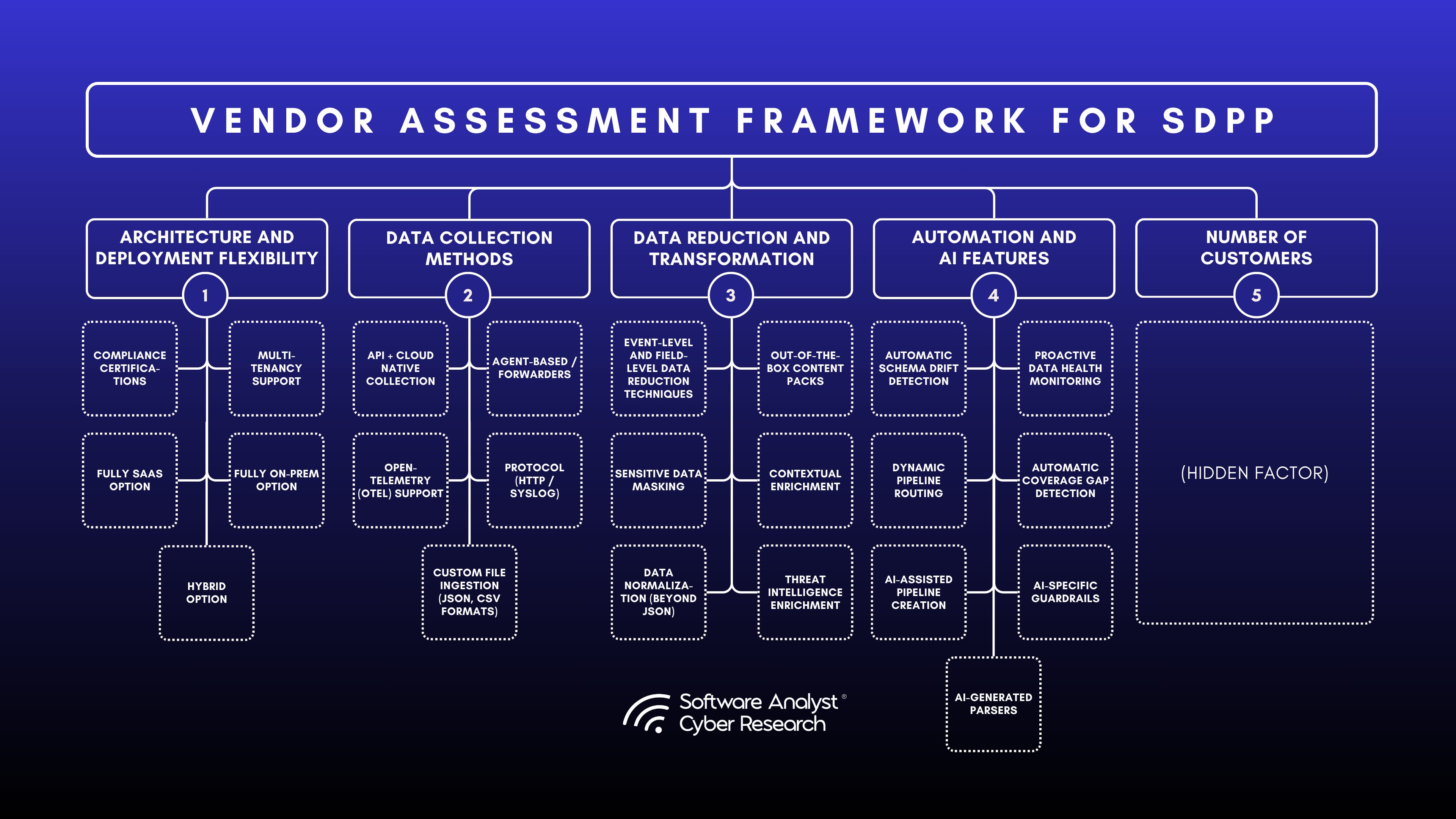
Vendors

Disclaimer: The image above is not depicted by exact ranking. Please see the ranking below. Spreadsheet with Technical and GTM assessment. Note that in-depth details are not contained within the sheet to maintain clean format but the details are covered within in each vendor’s section to prove how these rankings were made.
From our in-depth analysis, we found the pipeline platforms to rank as below –
Overall Market and Category Leader: Cribl
Pipeline Leaders: Databahn, Datadog OP, Abstract Security, Observo AI, Onum
Emerging Leaders: Cetu, VirtualMetric, Tenzir, Axoflow, Datable, Realm Security
Innovators: Brava, Beacon Security
The following top vendors were evaluated with a thorough platform demo, in-depth questionnaire (the answers of which were verified via demo and screenshots) and direct customer / practitioner feedback.
In alphabetical order and no particular ranking, all details on vendors below —
Abstract
Abstract defines itself as a modular, vendor-neutral security data platform that merges pipeline flexibility with early-stage detection. Their focus is on “shift left” threat detection, bringing analytics closer to the data source before it reaches the SIEM layer. Abstract Security’s strength and core differentiator lies in its threat detection capabilities, delivered by in-house research group, ASTRO, which builds and maintains out-of-the-box detection content and indicators of compromise. Abstract is one of the few SDPP vendors with native detection depth in pipeline, in addition to pipeline data routing capabilities.
Voice of the Customer
We interviewed a customer of Abstract Security to share their experience with Abstract and their vision for such a platform.
Life before Abstract
“We were in the process of moving from an on prem SIEM solution to a cloud SIEM. What we found that is that the current data usage, if we lift and shifted, would be 2x our annual budget, each month! So we had to figure out how to get the data we needed to our cloud SIEM, meet requirements, but also meet the budget. Exactly what the original use case was. Replacing on-prem SIEM to cloud SIEM, control costs, and really understand the logs. Because of Abstract we have been able to store more data, and at the same time reduce our storage, thus saving money.”
Most used capabilities within Abstract
“Abstract allowed us to understand what data was coming in, letting us determine what we needed, compress that data, and then move it into our cloud SIEM. We had some sources that we were able to reduce and compress over 90% of the original log size.”
What they’d like to see more of
The customer’s early feedback referenced local replay options, which Abstract has since delivered through Lake Villa’s tiered storage and hybrid replay capabilities. “We do have some large on-prem storage clusters. What our ideal solution would be is the ability to store logs on prem as well, and allow the data to be replayed to the cloud SIEM as needed. Basically bulk storage options to keep data around that isn’t worth the cloud storage costs.”
Architecture and Deployment Maturity
Abstract offers flexible deployment options supporting SaaS, managed SaaS and hybrid.
The architecture is split into “Console” which is delivered in SaaS and “Pipeline Engine” which can be deployed in SaaS or can be self hosted.
Console can be delivered as SaaS (from Abstract) or can be deployed within customer’s cloud environment (AWS, GCP, Azure) while being operationally managed by Abstract – on-time upgrades, health monitoring and resiliency. The core engine runs in the cloud (customer or Abstract hosted), but forwarders can also be deployed in customer environments (cloud or on prem).
- Marketplace: Available across AWS, GCP, and Azure.
- MSSPs: Abstract provides multi-tenancy with role-based and event-level access controls to support MSSPs. Partnerships in place, but exact list unknown. Company is currently engaged with a Big Four firm on deployment.
- Compliance: SOC2 Type 2 and are working on Fedramp
Pricing
Abstract uses flexible, consumption-based pricing with options for SaaS-hosted and customer-hosted deployments.
Hosted by Abstract (SaaS)
- Ingestion-based pricing within a broad range to avoid frequent overage charges
- Each plan includes up to 1 TB of excess data, with true-up at renewal
Customer-Hosted Deployments
- Enterprise licensing not tied to ingestion
- Pricing based on deployment size and infrastructure footprint for predictable spend
Pricing Assistance
- 1 TB of leeway for SaaS plans before adjustments are needed
- Cost planning support on preliminary calls, including custom estimates based on data volume and architecture
- Hybrid model gives customers SaaS-style simplicity while enabling local edge processing for cost, performance, and compliance benefits
Data Collection and Integrations
Abstract supports multiple data collection methods.
Customers can run Abstract in their own cloud or use a hosted console, with optional on‑prem forwarders for local processing. Integrations are largely built in‑house and designed to be no‑code in the UI, with exportable YAML and Python for teams that prefer code. Abstract emphasizes deep SaaS and cloud integrations where APIs and schema drift make dynamic content more valuable than basic transport-only connectors.
- Local forwarder and OTEL collection: Lightweight forwarders run on premises or in customer VPCs to collect and pre process data close to the source. Abstract supports OpenTelemetry compatible listeners and OTEL collectors for standardized collection in hybrid environments.
- API based agentless collection: For SaaS, cloud platforms, and managed services, Abstract performs authenticated API pulls on a schedule. This is a core focus area, with deep coverage for complex SaaS sources and cloud services where schemas change frequently.
- Webhook / push based streaming: Where native push delivery exists, Abstract receives events via HTTP webhooks for near real time ingestion, reducing latency for event driven systems.
- Broker and stream integrations: Abstract integrates with enterprise messaging and streaming systems such as Kafka, Kinesis, Pub/Sub, Event Hubs, and notification queues like SNS and SQS to support high throughput pipelines.
- Syslog, HTTP, and object storage: Abstract accepts generic transports including Syslog, HTTP, and object storage buckets for bulk or batched ingestion, with parsers and normalization to OCSF, ECS, or custom schemas. The platform distinguishes complete integrations that include parsers, pipeline functions, detections, and dashboards from generic transport only feeds.
Number of integrations: Abstract currently supports 242 out of the box integrations with expanded opportunity, because of collection methods supported.
Core Pipeline Capabilities
Diving deeper into core pipeline capabilities.
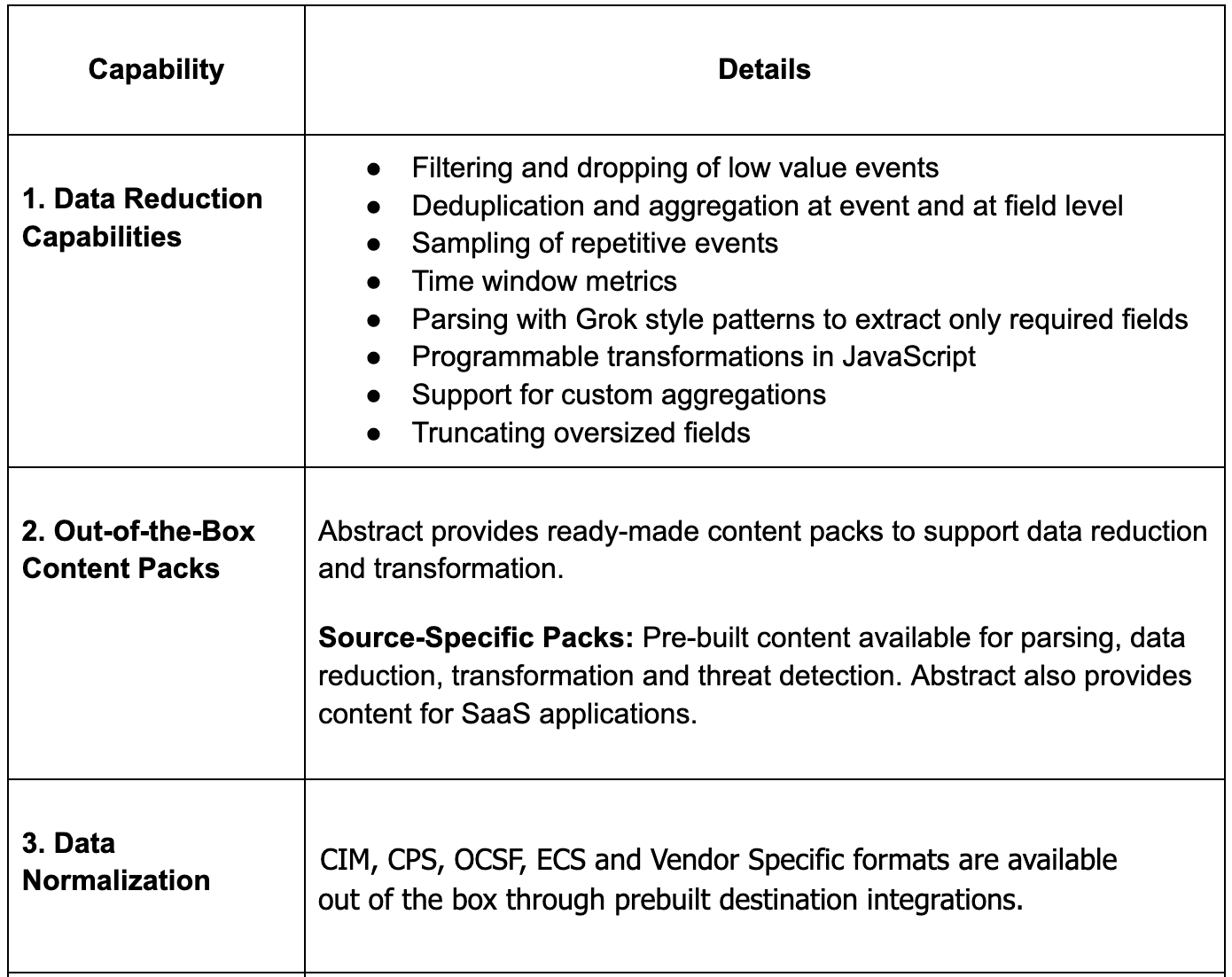

Additional Pipeline Capabilities
- Immutable raw data storage: For compliance
- Local compression & lightweight processing by forwarders
- Stream X-Ray Recommendations: The pipeline engine continuously analyzes telemetry in-stream and surfaces the most valuable fields.
- Observability Convergence: Pipelines treat security and observability telemetry equally, making it possible to blend logs, metrics, and traces into a single streaming fabric.
- Exporting/importing of pipelines as YAML for version control and portability
Pipeline Building Experience
- Automatic Default Creation: Pipelines are auto-generated when new data sources connect, with schemas detected and flows built without manual setup.
- Manual Configuration: Users can adjust or extend pipelines for custom filtering, enrichment, or routing as needed.
- Drag-and-Drop Builder: A visual canvas lets analysts connect sources to destinations using a simple drag-and-drop interface, eliminating code.
- Pipeline DSL (YAML): Advanced users can define transformations and routing declaratively for CI/CD automation and version control.
AI Maturity
ASE, the Abstract Security Engineer (an AI assistant), enables natural language pipeline creation, integration setup, and schema mapping with optional YAML or JS export for advanced users. It automates schema normalization, drift correction, and propagation across pipelines, reducing manual upkeep. ASE also extracts indicators of compromise from unstructured sources to continuously enrich the Intel Gallery.
AI correlates entities, automates data redaction, and optimizes enrichment depth to support real-time detection and compliance filtering. Stream X-Ray adds AI-driven observability by identifying high-volume or anomalous sources and recommending reduction actions. ASE also serves as the analyst interface, summarizing detections and insights in natural language, with plans to expand into full analytic narratives for enhanced explainability.
Additional AI Capabilities on Roadmap
Abstract is building Sigma-based AI rule conversion and automated correlation design under its detection engineering roadmap. Generative detection narratives and behavioral modeling are also planned.
Data Privacy with AI:
- Access control and isolation: Multi-tenant by design with role-based and event-level access controls, allowing MSSPs to grant visibility while keeping tenants strictly separated.
- Human oversight model: “Insights” workflow correlates noisy Findings into analyst-ready Insights where humans and AI collaborate on investigation and enrichment.
Integration Health Monitoring
Additional Capabilities beyond Pipelines
This section notes capabilities that the vendor may provide beyond pure pipeline features
Data Lake- Lake Villa
Abstract’s Lake Villa is a built-in, smart data lake designed for high-performance storage and real-time querying of security telemetry. It doesn’t need rehydration delays and supports replay to other destinations or the Abstract Streaming Correlation Engine. Lake Villa can be hosted by Abstract or deployed in any major cloud or private environment, with tiered storage (hot, warm, cold) for cost-optimized retention. Fully integrated with the Abstract pipeline, it enables real-time queries on enriched, normalized data while remaining open and extensible for forwarding to external SIEMs or data lakes.
Tiering models: Hot, Warm and Cold
Threat Detection Engine
Abstract runs detections directly in the data stream with out of the box threat detection content. It measures detection effectiveness by mapping visibility gaps to real data sources and rules. The Model Service enriches events with identity, asset, vulnerability, and threat intelligence in a unified data fabric. Stream X-Ray recommends which fields to filter or aggregate, improving signal quality and reducing false positives
Vision
Abstract’s vision is to be a decomposed SIEM of the modern era that combines: a security data fabric that unifies observability, AI powered detection, and response in a modular architecture. Their vision is to be the world’s first composable SIEM. They want to challenge the traditional SIEM model, with a modular architecture, reimagining what a security operations platform should look like in an age of exploding telemetry, multi-cloud sprawl, and AI-driven adversaries.
Analyst Take
Here’s where what we see as major strength and opportunity for improvement for Abstract –
Strengths
Abstract Security stands out for its streaming-first design that detects threats as data flows, cutting response times and lowering dependence on analytics at SIEMs. Its built-in health monitoring and schema drift automation keep pipelines stable without constant tuning, a mark of operational maturity. Stream X-Ray shifts the focus from collecting more logs to collecting high quality ones, improving both fidelity and cost efficiency. Lake Villa, is another area where customers can utlize in-house capabilities without needing an external dependency.
All in all, Abstract could be a good fit for organizations looking for a modular architecture that bridges security data pipeline capabilities with analytics and storage.
Areas to Watch:
Abstract’s opportunity lies in strengthening the autonomy, transparency, and breadth of its AI capabilities. While ASE assists with schema and pipeline management, evolving them toward self-healing and predictive automation would bring the platform closer to AI maturity. Adding clearer audit trails, lineage tracking, and data-handling guardrails would improve AI privacy trust and compliance readiness. Finally, Abstract’s ambition to replace the SIEM stack is bold but challenging for an SDPP vendor entering a market dominated by mature players like Splunk. The vendor reported that it recently secured a large enterprise win in which its composable SIEM was selected following a direct comparison with a leading SIEM provider. However, in an established SIEM industry with years of maturity, demonstrating consistent outcomes across a broader range of customers and environments remains important for assessing its overall competitiveness. Expanding coverage analytics, and federated search would also round out functionality comparison for such a vision. To succeed, the company will need to continue to demonstrate end-to-end depth across detection, data management, and operational scalability.

Axoflow
Axoflow is one of the promising newcomers in the Security Data Pipeline Platforms category. The company raised a $7M seed round earlier this year and has been innovating quickly. Axoflow provides an automated approach to security data ingestion, focusing on source identification, curation, and routing rather than regex-driven configuration. Its support for hybrid and air-gapped deployments, along with an agent-agnostic collection model, makes it suitable for organizations with heterogeneous environments and stricter control requirements. The use of supervised AI for classification and natural-language pipeline creation shows a clear focus on reducing manual effort in managing telemetry pipelines.
Architecture and Deployment Maturity
Axoflow offers flexible deployment options supporting SaaS, hybrid, self‑managed, and air‑gapped models. Console and Pipeline components can run in any mix to meet environment and control requirements.
- Marketplaces & Vendor Programs: Splunk Partnerverse, Cisco partner, Sumo Logic partner, only security data pipeline vendor with Google Private Service Connect; AWS and additional Google integrations in progress.
- MSSP Partners: DTAsia, PCSS, Sekom, SOS, WavePort Security, Kyndryl, Ether Gulf Enterprise, CloudSpace, Securelytics, Stefanini.
- Compliance: SOC 2 Type II and ISO 27001.
Pricing
Ingestion-based licensing model aligned to the volume of data or number of data sources onboarded.
Pricing Assistance: None provided.
Data Collection and Integrations
Axoflow’s platform supports multiple collection methods. It collects data through various protocols, agents, and infrastructure compatibility.
- Protocols: Axoflow can receive logs via syslog , HTTP , and other protocols.
- Agents: Axoflow supports multiple agent types for data collection, including native agents and OTEL collectors. Specifically, it supports OpenTelemetry collector-based agents for Windows/Linux.
- API Integrations: The platform leverages API-based pulling for collecting data from cloud sources. It supports API integrations using API pull agents for cloud sources including CloudWatch and Azure Event Hub.
- Infrastructure Compatibility: Axoflow is compatible with existing infrastructure , including examples such as syslog-ng, Splunk UF/HF. The system integrates with over 150 security products as data sources.
- Deployment for Collection: The AxoRouter (processing engine) can receive logs. The entire Axoflow console, data sources, and processing engine can be deployed locally. Installation requires only a one-liner on a Linux box or Kubernetes.
Total number of integrations out of box: 154 integrations, the number can be higher due to ingestion methods supported.
Core Pipeline Capabilities
Additional Pipeline Capabilities
- Log Tapping and Side-by-Side Debugging: Axoflow allows users to inspect raw and parsed data simultaneously, with highlighting to show how each pipeline step transforms the event.
Pipeline Building Experience
- FilterX Pipeline Syntax and Declarative Routing Model: Axoflow uses FilterX, a domain-specific language for log processing, along with declarative routing driven by automatically applied labels. This allows users to define transformations and routing logic without relying on regex-heavy configurations.
- Visual Pipeline Builder: Axoflow provides a visual interface that allows users to create pipelines using point-and-click elements, reducing dependence on scripting and simplifying troubleshooting.
- AI-Assisted Pipeline Creation: Axoflow supports natural language search and pipeline building, enabling users to describe goals in plain language and have the system generate corresponding pipeline logic. An integrated AI assistant provides contextual help and documentation.
AI Maturity
Axoflow positions its platform around a more advanced level of AI maturity by taking responsibility for maintaining data pipelines rather than using AI as just an assistive layer. The company’s AI capabilities center on an AI assisted decision tree that identifies data as it flows through the platform and applies classification labels that drive routing, curation, normalization, and reduction decisions. This classification engine uses supervised AI to adapt to changes in source data and manage schema drift without manual tuning. This autonomous change capability removes human in the loop supervision and reflects a higher level of AI maturity.
AI also supports natural-language search and in-product pipeline building, allowing users to describe transformations or routing behavior through NLQs rather than written logic.
An AI assistant is built into the console to help with documentation, guidance, and configuration support. Axoflow also applies automated, source-aware reduction and curation informed by its classification logic, improving downstream detection quality and reducing noise before data reaches the SIEM. Additional AI features, including stream-processing and threat intelligence enrichment, are in progress.
Data Privacy with AI: Provided by tenant level separation.
Integration Health Monitoring
Additional capabilities
This section notes capabilities that the vendor may provide beyond pure pipeline features
Data Lake – Multi-Layer Storage Architecture
Axoflow supports scalable ingestion and long-term analysis through a layered storage model. AxoStore provides edge storage used for local buffering and troubleshooting, Axoflow Locker serves as a standalone log-store appliance for remote operations, and AxoLake delivers a petabyte-scale tiered data lake for extended retention and analytics.
Vision
Axoflow’s vision is to create a decentralized SIEM model where some of the SIEM functions like curation, storage, policy enforcement, and analytics are no longer done in the SIEM but move closer to the pipelines, where data is streaming through. AI supports the process by automating key steps, acting as an enabler rather than a shortcut.
Analyst Take
Here’s where what we see as major strength and opportunity for improvement for Axoflow
Strengths
Axoflow’s strengths lie in its automation depth and operational flexibility. The platform offers broad deployment choice across SaaS, on-prem, hybrid, and air-gapped environments, which positions it well for regulated or distributed estates. Its classification-driven engine is also a differentiator which handles reduction, normalization, and routing without regex or manual tuning, and the ability to surface both raw and parsed data simplifies troubleshooting. Integration health is another strong point, with detailed metrics on drops, delays, queues, and host resources, paired with automatic source inventory to reduce blind spots. Axoflow also brings an uncommon storage footprint for a pipeline vendor, offering edge collection, a standalone log-store appliance, and a tiered lake for long-term retention. Combined with broad ingestion support, the platform’s ambition to minimize operational overhead and take more from the SIEM adjacent capabilities are set on track.
Areas to Watch
Axoflow’s schema handling is automated, but it lacks explicit drift alerting, which may matter for teams with strict governance or change-control requirements. The company is still early in its market maturity, though the leadership team’s background seems promising. Axoflow can invest in areas like out of box content packs, AI capabilities and features beyond reduction and curation. Pricing support appears less structured as well, with limited guided TCO tooling, which can slow enterprise evaluation. While the platform has strong foundations, similar to a typical emerging entrant in this category, it will need to expand its ecosystem presence, operational guardrails, and packaged content to execute on it’s vision.
Beacon Security
Beacon Security is a promising newcomer to the security data pipelines market category. They came out of stealth just this month (November, 2025). Beacon enters the security data pipeline space with a focus on content-aware “Recipes,” agentic AI assistance, and stable ingestion mechanics aimed at improving data quality while controlling cost. Based on early materials and briefings, the platform is positioned as a security-focused data fabric built to reduce operational overhead and support downstream detection and investigation across SIEMs, data lakes, and emerging AI workflows.
Voice of the Customer
We were able to interact with a customer ( a US based financial firm), of Beacon asking about their experience with the platform. Here is what they said –
Life before Beacon
“The main challenges our organization faced prior to adopting Beacon were related to infrastructure burden, standardization, and log volume management. In the world of endless SaaS applications, every vendor provides logs differently, or sometimes not at all. Some logs come via webhook, others might use an external syslog over different protocols, and most are polling APIs. On top of collection issues, there is no agreed upon standard for log normalization (schema). We tried to address this internally using open-source tooling, but we ran into significant limitations. It was difficult to gather logs from one-off vendors in an elegant or efficient way. This required us to build a lot of custom infrastructure internally just to support every single log source. The other major issue was the log volume problem. There is so much data flying around, and while we can’t simply not gather the data, we also don’t need absolutely everything. We needed a reliable way to consolidate logs without sacrificing meaningful information. Beacon’s capabilities exactly address these specific challenges.
The future of Beacon within our organization involves expanding its presence to cover internal data. We currently still have quite a few logs that are internal and do not yet go through the platform. While the collection of these internal logs isn’t the primary issue, we plan to ingest these logs through Beacon as well. We would utilize this expansion specifically for the purposes of normalization, log reduction, ultimately leading to better data at a lower cost.”
Most used capabilities within Beacon
“Beacon’s capabilities were the exact solution to our organizational challenges. The top capabilities we rely on are:
- Comprehensive Log Gathering: Beacon can gather logs from essentially any system in any way we ask them to.
- Normalization: They will normalize the logs to any schema we request using their internal AI agent.
- Log Volume Reduction: Beacon helps us reduce log volume by analyzing the logs and combining similar logs within short periods of time.”
What they’d like to see more of
“Data volume and SIEM costs these days are astronomical – we would love to see a combination of in-pipeline detections paired with a full self service feature to send logs directly to cold storage while having the ability to rehydrate them to send to our SIEM. This would drastically reduce our SIEM spend while not lowering our security posture.”
Architecture and Deployment Maturity
Beacon provides flexible deployment options. It’s architecture is split into a SaaS control plane with either SaaS managed engine or customer-hosted engines deployed in Bring Your Own Cloud (BYOC) or on-premises environments. Pipelines include persistent queues, replay, and exactly-once delivery to ensure durability and reliability.
- Marketplace: Beacon is listed in AWS Marketplace
- MSSPs: Collaborates with MSSPs in joint projects for customers (not co-sell).
- Compliance: SOC 2 Type II, ISO/IEC 27001, HIPAA
Pricing
Ingestion-based pricing model.
Pricing Assistance: The ingestion plan takes into account the types and value of data sources.
Data Collection and Integrations
Beacon allows normalization and routing across environments without sending raw log data outside customer control. Supported sources include APIs, Syslog, Webhooks, OpenTelemetry, and major cloud storage platforms. Normalization aligns to schemas such as OCSF, ECS, CIM, UDM, and ASIM, with multi-destination routing supported through exact-once delivery and persistent queuing.
Ingestion Approach
- OTEL Collectors: Supports OTEL collectors for standardized, vendor-neutral telemetry collection across cloud and on-prem environments.
- API-Based Integrations: Connects directly to platforms via REST APIs, enabling agentless collection from services like AWS, Azure, and Google Cloud. Also pulls data from cloud storage platforms including Amazon S3, Azure Blob Storage, and Google Cloud Storage.
- Syslog and Raw TCP: Ingests data via traditional syslog (UDP/TCP) and raw TCP sockets, supporting legacy infrastructure and security appliances.
- WebSocket and Webhook: Handles event-based ingestion via WebSocket streams and HTTP webhooks for modern, real-time data sources.
- Filesystem and STDIN: Supports file-based log ingestion and standard input streams, enabling local testing or lightweight deployment scenarios.
- Forwarders and Event Streams: Integrates with log forwarders like Vector and streaming platforms such as Azure Event Hub, AWS Kinesis, and Kafka for high-throughput environments.
Integrations Count: Over 100 when grouped by types of events within each integration and the collection method supported.
Core Pipeline Capabilities
Diving deeper into core pipeline capabilities
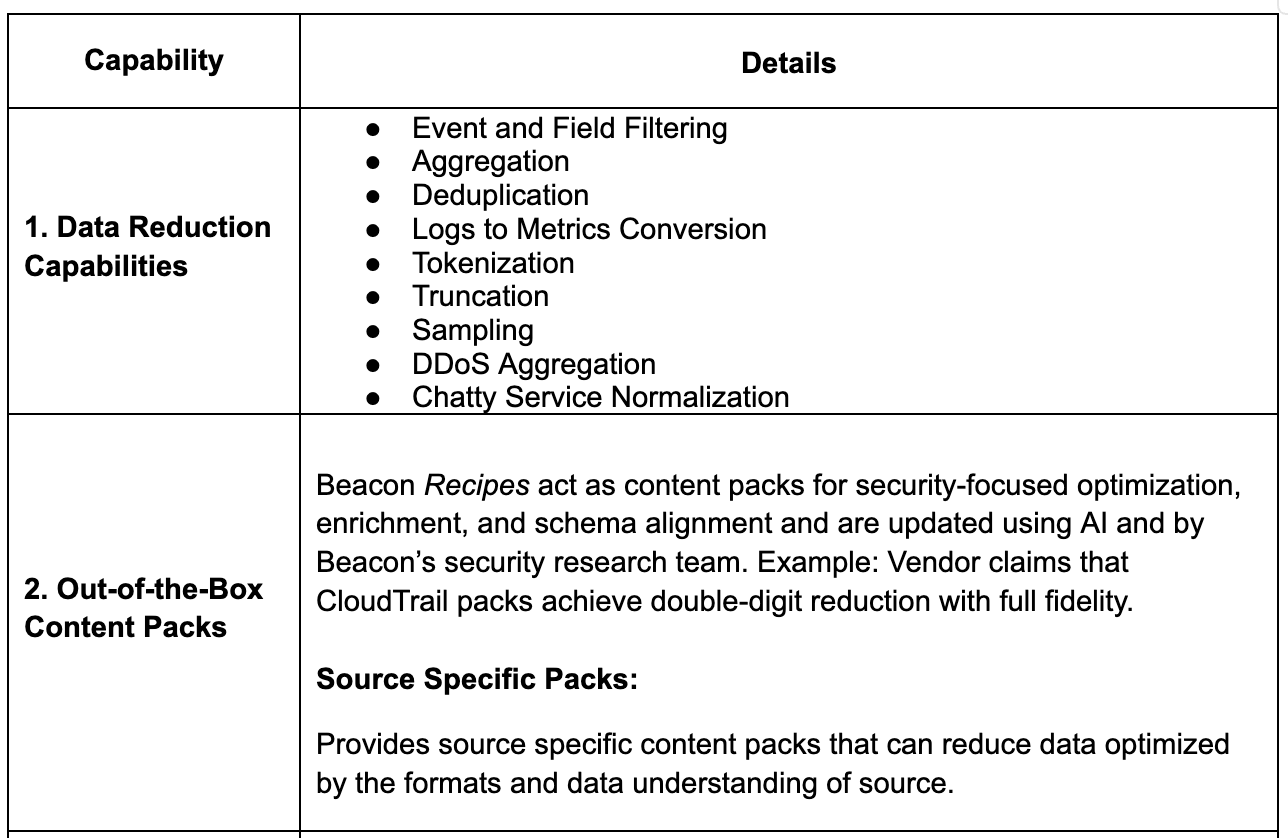


Additional Pipeline Capabilities
- AI-Guided Routing and Logging Posture: Beacon’s AI-driven Logging Posture capability identifies important telemetry gaps and recommends routing missing but relevant data to appropriate analytics destinations.
- Late Arrival and Exactly-Once Processing: Supports lossless data delivery with stream correlation, replay handling, and tolerance for out-of-order events to ensure reliable and complete ingestion.
- Live Recipe Validation and Decision-Supporting EDA: Enables real-time transformation-level preview, data analysis (EDA), optimization metrics, and testing of transformations. Users can verify schema accuracy, understand recipe logic, and customize transformations based on statistics and context.
- Modular Cloning: Allows users to duplicate and reuse existing pipelines or Recipes across environments for faster scaling.
- Regex-Based Data Shaping: Provides flexible parsing and field extraction for complex or unstructured log formats.
- Governance and Masking: Applies field-level classification and masking for sensitive fields to maintain compliance.
Pipeline Building Experience
- AI Chatbot Interface: AI assistant for guided pipeline creation.
- Visual Workspace: Build and manage pipelines using a visual editor.
- JSON/YAML Upload: Import configurations directly by uploading structured JSON or YAML files.
- Point-and-Click Recipes: Use prebuilt Beacon Recipes with a simple interface to apply transformations without writing code.
AI Maturity
Beacon incorporates multiple layers of agentic and AI-driven intelligence across its platform. This includes schema-aware mapping and validation for target formats like ECS and OCSF, as well as Recipe recommendations that guide enrichment and pipeline optimization. Its logging posture and data discovery features help identify critical telemetry that may be missing from current collection, supporting improved detection coverage.
The platform’s agentic fabric intelligence is also oriented toward building entity and context graphs to support future AI-SOC workflows. BeaconBot, currently integrated with Slack, allows users to query platform state via API. The roadmap includes expanding this capability to support controlled write operations on data streams, also via MCP server, further embedding automation into pipeline operations.
Data Privacy with AI: Beacon’s BYOC and on-premises models keep customer data within their environment.
Integration Health Monitoring
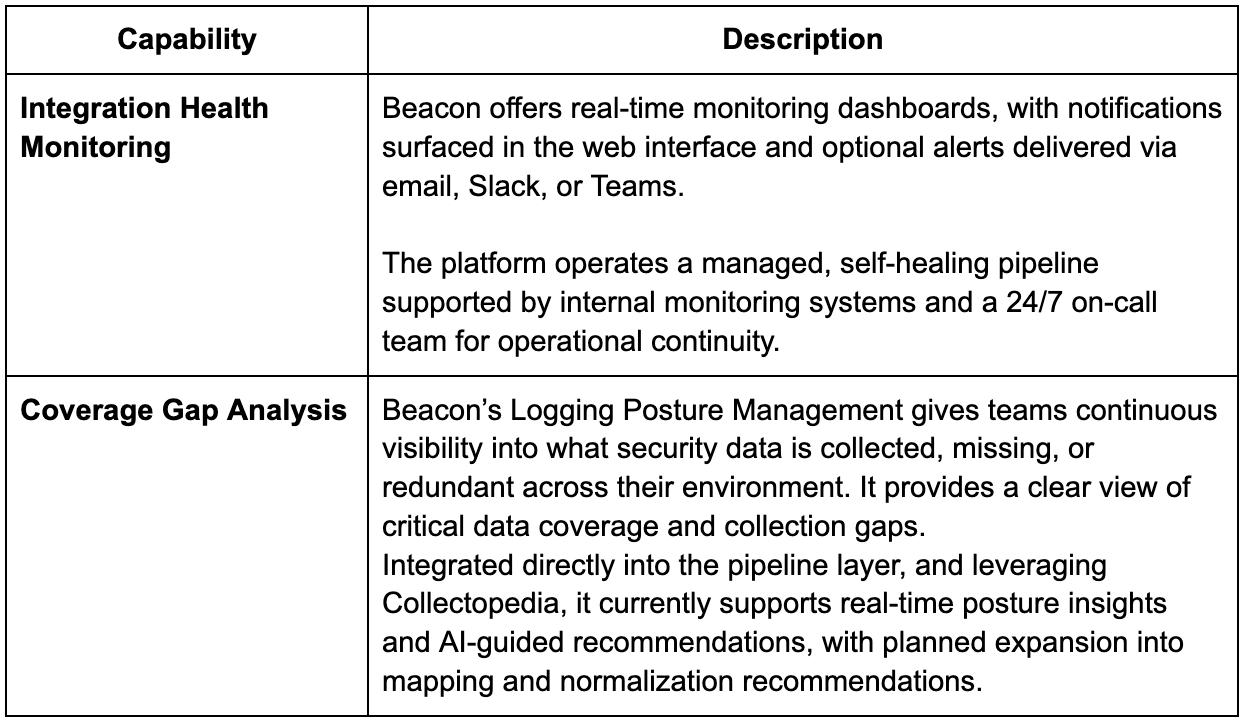
Additional Capabilities
This section notes capabilities that the vendor may provide beyond pure pipeline features.
Collectopedia
Beacon maintains Collectopedia, a structured knowledge base that maps security data sources, schemas, and field semantics to use cases, MITRE ATT&CK tactics, and investigative value. It supports Beacon’s normalization, enrichment, and discovery features by helping both AI agents and users understand the purpose and relevance of each field. End users interact with Collectopedia through capabilities like telemetry discovery, compliance mapping, and MITRE tactic-level visualizations.
Vision
Beacon’s goal is to become the security data and context layer, which utilizes pipelines and Beacon Fabric to unify collection, optimization, normalization, enrichment, and governance across environments. It is evolving toward enabling both analysts and AI systems to reason over high-quality, contextualized security data.
Analyst Take
Here’s where what we see as major strength and opportunity for improvement for Beacon –
Strengths:
Beacon is strongest at the intersection of security context and pipeline engineering. Its practitioner-defined Recipes, schema mapping to ECS and other standards, and support for exactly-once delivery and late-arrival handling offer reliability and flexibility. Logging Posture and Data Discovery help teams quickly identify what telemetry to collect and where to route it, reducing setup time and cost. Beacon avoids native storage and indexing by design. Data stays in the customer’s existing SIEM, object store, or data lake, while Beacon handles routing, normalization, and enrichment. This supports portability and aligns with federated analytics models, though it requires integration with downstream tools for search. For teams prioritizing AI-assisted posture, schema alignment, and operational control across open telemetry environments, Beacon offers a differentiated approach.
Areas to Watch:
Coverage signals are available through Logging Posture and Data Discovery, though a dedicated coverage dashboard is not yet available. It is planned in the near term roadmap and has been confirmed in preview. Programs with reporting or governance needs should assess the current level of depth. Detection content is currently destination and partner led, which keeps the focus on data fabric and context, but buyers expecting bundled detections should evaluate how well this aligns with their content strategy. Beacon’s approach to schema drift is to absorb changes by default through Recipe updates rather than surfacing them by default, to users. This reduces noise and day to day toil for most teams, but those who prefer more visibility will need to adjust the defaults to enable it. AI capabilities are a growing area of interest within the pipeline industry, and we look forward to seeing continued investment from Beacon in this area as they grow.

Brava
Brava is currently in stealth and takes an interesting approach to telemetry routing. While they don’t position themselves as an SDPP (security data pipeline platform), they address similar use cases extending beyond routing and cost reduction to also improve threat detection and overall telemetry efficacy. The platform can operate alongside an SDPP or as a standalone solution.
Brava positions itself as a telemetry efficacy layer that sits just in front of security data pipelines and SIEMs. Its platform uses AI-driven attack simulation, a continuously updated knowledge base of log signatures and even looks through undocumented APIs, to uncover how attacks expose themselves across telemetry. Brava enriches, filters, aggregates and tunes detection for an optimized threat detection process while reducing costs.
Architecture and Deployment Maturity
Brava’s management console is delivered as a multi-tenant SaaS platform hosted and operated by Brava, providing the user interface, API access, TTP coverage mapping, and configuration management. Users connect securely through a browser or API, with all configurations and metadata stored in Brava’s cloud environment.
The data pipeline engine can run as a managed SaaS service or be deployed within a customer’s environment, such as a cloud account, VPC, or other infrastructure. It handles log collection and forwards data to the Brava platform for normalization, reduction, and enrichment, where Brava maintains read access.
A fully on-premises version of the pipeline engine is on the roadmap.
- Marketplace: AWS, also highly integrated with Cribl (Cribl Packs).
- MSSPs: Mobia.
- Compliance: SOC2, ISO27001
Pricing
Size of the environment.
Pricing model is based on the size of the environment (e.g. number of cloud resources, number of firewalls, etc.). The goal is to be predictable.
Pricing Assistance: Pricing calculator: Brava provides an estimate pricing calculator.
Data Collection and Integrations
Brava supports multiple data collection methods. Brava integrates with major cloud and identity sources such as AWS, Azure, GCP, Okta, Entra ID, and custom HTTP feeds for unsupported data like syslog. Data can be routed to destinations like Splunk, Microsoft Sentinel, Cribl, Snowflake, and major cloud storage services. Automation and ticketing integrations include Tines, ServiceNow, Slack, Teams, and Opsgenie.
- API-Based (Agentless) Integrations: Brava connects directly to major cloud and identity platforms such as AWS, Azure, GCP, Okta, Entra ID/Active Directory, and O365 through API-based ingestion. This method removes the need for local agents and provides secure, low-maintenance data collection.
- OpenTelemetry (OTEL) and Streaming: Supports ingestion via OpenTelemetry collectors and Kafka streams, allowing standardized telemetry capture from modern applications and infrastructure. This approach ensures compatibility with existing observability and security data pipelines.
- Custom HTTP Ingest: Offers flexible HTTP endpoints for proprietary, legacy, or unsupported data sources, including syslog, netflow, and custom application logs.
- Push Models: Data can be pushed or streamed to Brava.
Total number of integrations out of the box: 29 but can be expanded based on collection methods supported.
Core Pipeline Capabilities
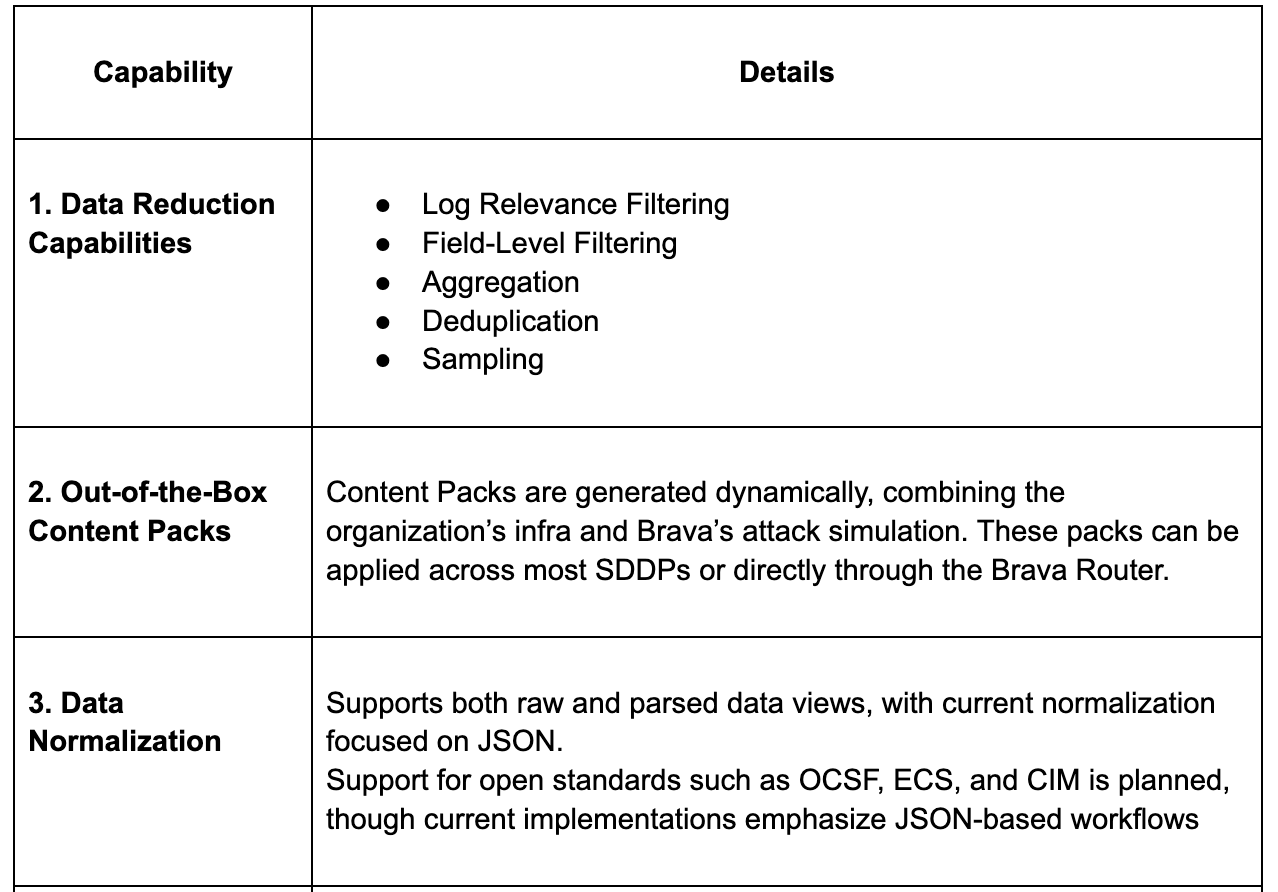


Additional Pipeline Capabilities
- Seamless Retrieval from Low-Cost Storage: Enables users to query logs stored in lower-cost tiers directly from their SIEM, maintaining the same interface and experience without additional tools or knowledge of data location.
- Natural Language Querying: Allows users to run natural language searches within the SIEM, eliminating the need to specify indexes or write query syntax.
Pipeline Building Experience
- Yaml Files: Brava represents and builds its pipelines as YAML files. They do mention that this is not its primary focus. The platform is typically deployed alongside other pipeline tools, adding an intelligence layer that identifies gaps and enhances pipeline efficiency.
AI Maturity
Brava uses an AI-driven efficacy engine that evaluates logs at the field level, combining insights from active attack simulations with a continuously updated knowledge base. These simulations run both broad and deep attack paths, mapping telemetry to the MITRE ATT&CK framework to assess whether each log contributes meaningfully to detection or investigation.
Brava also monitors SIEM analytics to identify whether required logs are being ingested, helping teams surface gaps that impact detection coverage. This continuous feedback loop supports intelligent routing decisions and allows Brava to deliver a pipeline’s data reduction value.
Data Privacy with AI: Tenant isolation is built into the SaaS architecture. The platform supports RBAC and integrates with enterprise identity providers. Access is provided through a secured UI and API.
Integration Health Monitoring
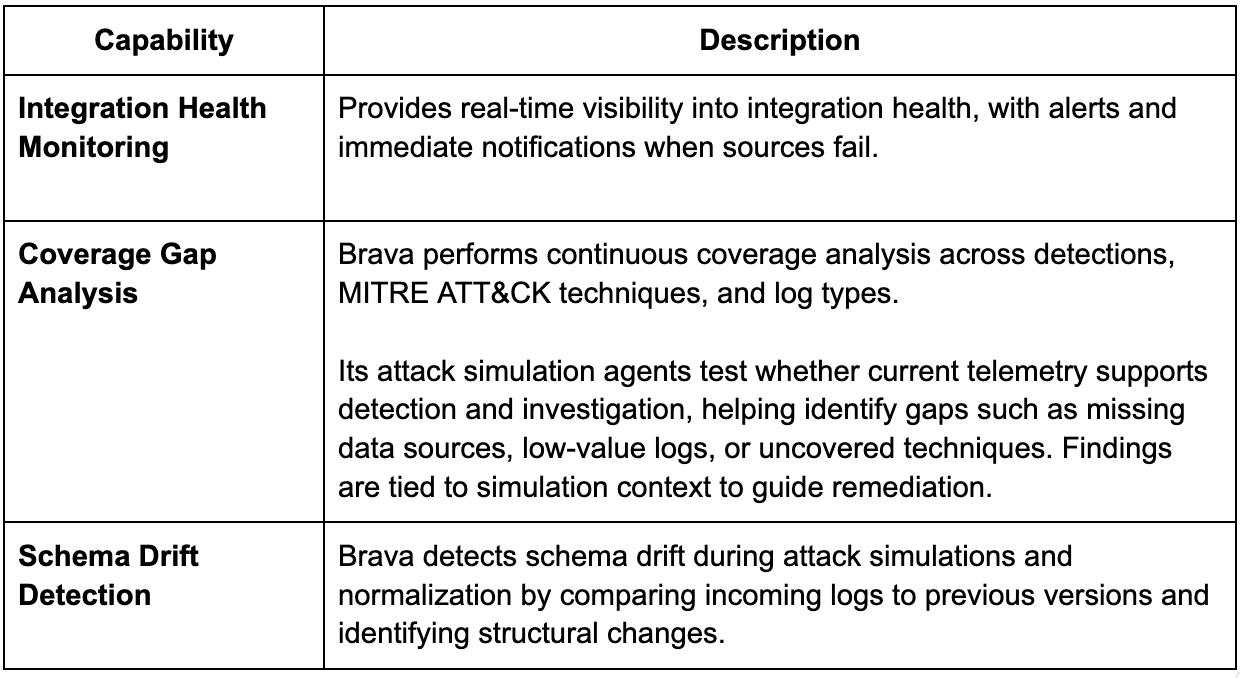
Additional Capabilities beyond Pipelines
Brava provides these additional capabilities beyond core pipeline features.
Attack Simulation for Coverage Testing
Brava runs large-scale attack simulations across both sandboxed environments and the customer’s own infrastructure. These simulations test whether the current telemetry and pipeline configuration can support detection and investigation at scale.
Seamless Search and Retrieval from Storage platforms
Brava enables natural language queries from within the SIEM, removing the need for users to specify index names or write complex query syntax. Users can query archived logs stored in low-cost tiers directly from their SIEM interface. The retrieval is transparent, no need to manage storage locations or switch tools.
Vision
Brava’s vision is to build an AI-driven security data fabric that improves the way teams manage telemetry across their pipeline and SIEM. Rather than replacing existing tools, the goal is to evaluate each log at the field level, map it to MITRE, and use continuous attack simulation to inform routing, enrichment, and storage decisions. The longer-term direction is toward agentic workflows, where the platform actively identifies gaps, reduces noise, and shapes what gets sent to the SIEM based on actual detection value.
Analyst Take
Here’s where what we see as major strengths and opportunities for improvement for Brava –
Strengths
Brava stands out for its focus on telemetry efficacy, using continuous attack simulation, and a living knowledge base from it to find gaps, add security context, and guide routing and reduction. This lets teams lower ingest costs without sacrificing detection coverage. Designed to run alongside existing SIEMs and pipelines, Brava reduces adoption friction and fits into environments using tools like Splunk, Cribl or Sentinel. It supports a wide range of integrations across cloud, identity, analytics, and automation platforms.
Features like SIEM-native log retrieval from low-cost storage and natural language querying help analyst workflows while optimizing data flow. Operationally, Brava offers tenant isolation, RBAC, SSO, and early marketplace and MSSP signals, making it a fit for teams prioritizing visibility, efficiency, and control.
Areas to Watch
Brava’s normalization is currently centered on JSON, with support for OCSF, ECS, and CIM still in progress. Integration coverage is growing but is an area to improve, and parser updates are still handled manually despite automatic drift detection. The YAML-based builder works but may limit accessibility as buyers look for natural language and validation tools. Overall, we believe that traditional SDPPs (such as those covered in this report) work much better as pure routers when a customer has many destinations.

CeTu
CeTu differentiates itself through context-aware SIEM analytics at scale, a low-latency data engine designed to operate at low cost, and a proprietary pattern-intelligence layer that improves with each deployment. The platform provides an AI-driven security data pipeline aimed at optimizing telemetry flow and reducing SIEM ingestion volume. The company’s broader vision is to develop a unified, AI-driven security data fabric that simplifies data management, enhances analytical context, and strengthens both security and observability workflows. This direction is intended to support organizations in maintaining a proactive security posture.
Voice of the Customer
Life Before CeTu
The customer described a growing operational burden associated with escalating log volumes and Microsoft-based SIEM ingestion costs. Prior to CeTu, the security team faced significant pressure to manage expanding telemetry from both IT and industrial environments without a scalable cost-control mechanism.
Most Used Capabilities Within CeTu
The customer reported that CeTu’s main value was its ability to improve detection efficiency through automated processing of high-volume log streams. In their case, the platform filtered out noise from overly verbose applications and produced a clearer and more actionable security signal. According to the customer, this contributed to a stronger detection posture.
The customer also observed a secondary outcome: a 60 to 70 percent reduction in log volume. This decrease lowered ingestion costs and made it possible to onboard additional systems without exceeding capacity, a practical need in data-heavy IT environments.
While the economic effects were notable, the customer emphasized that these results were a direct consequence of CeTu’s core function of increasing visibility, speeding detection, and reducing noise before it reached downstream tools.
What They Would Like to See More Of
While satisfied with cost reduction and noise control, the customer expressed interest in deeper detection-centric value, AI-driven rule optimization, and support for lower-cost analytical workflows on archived telemetry. The customer expressed interest in continued, deeper detection-focused capabilities, particularly around gap monitoring and AI-driven rule optimization, both of which, according to Cetu, his team has begun adopting. He also noted that he is looking forward to upcoming enhancements that will allow analytical AI workflows to run on lower-cost archival storage, confirming alignment with CeTu’s roadmap and long-term strategy.
Architecture and Deployment Maturity
CeTu offers flexible deployment options supporting SaaS, hybrid, and on-premise operation.
Their architecture is divided into Console (control plane) and Pipeline Engine (CeTU FLOW). CeTu Flow is the platform’s pipeline engine, designed to provide low latency and high throughput for large-scale data processing. It was developed by the company’s CTO, who applied experience from carrier-grade switching systems to create an architecture focused on efficiency. According to the company, the system delivers high performance while requiring comparatively limited infrastructure resources, resulting in lower operational costs. They also offer their own proprietary intelligence layer called CeTu Depth.
- Marketplace: CeTu is listed in AWS Marketplace, Azure Marketplace, Crowdstrike
- MSSPs: GuidePoint, Trace3.
- Compliance: SOC 2 certified.
Pricing
Ingestion based model.
Pricing Assistance: CeTu provides pricing calculators, but these are not publicly exposed today (used via sales / SE engagement rather than self-serve).
Data Collection and Integrations
CeTu unifies telemetry ingestion across cloud platforms (AWS, Azure, GCP), SaaS, IoT, and on-premises environments, providing a single framework for collecting and routing security data. Supported inputs include OpenTelemetry (OTEL), Syslog, CloudTrail, APIs, and custom HTTP endpoints.
CeTu’s ingestion approach can be characterized across these modes:
- Pre-Built Connectors: More than 400 connectors for SaaS, cloud, and infrastructure sources deliver parsed, normalized data out-of-the-box.
- Custom Connector Builder (HTTP Sources): A low-code tool for creating connectors to proprietary or uncommon APIs, extending coverage to internal systems.
- AI-Assisted Parsing: CeTu’s AI engine automatically structures unformatted or custom logs without regex or manual parsing, accelerating integration.
- Proprietary Forwarder Architecture: A high-performance forwarder designed for high throughput, low latency, and reduced infrastructure overhead.
- Agent-Based and Agentless Collection: Supports both agent and agentless data collection through OTEL collectors, APIs, and forwarders to match customer deployment models.
Core Pipeline Capabilities
Diving deeper into core pipeline capabilities
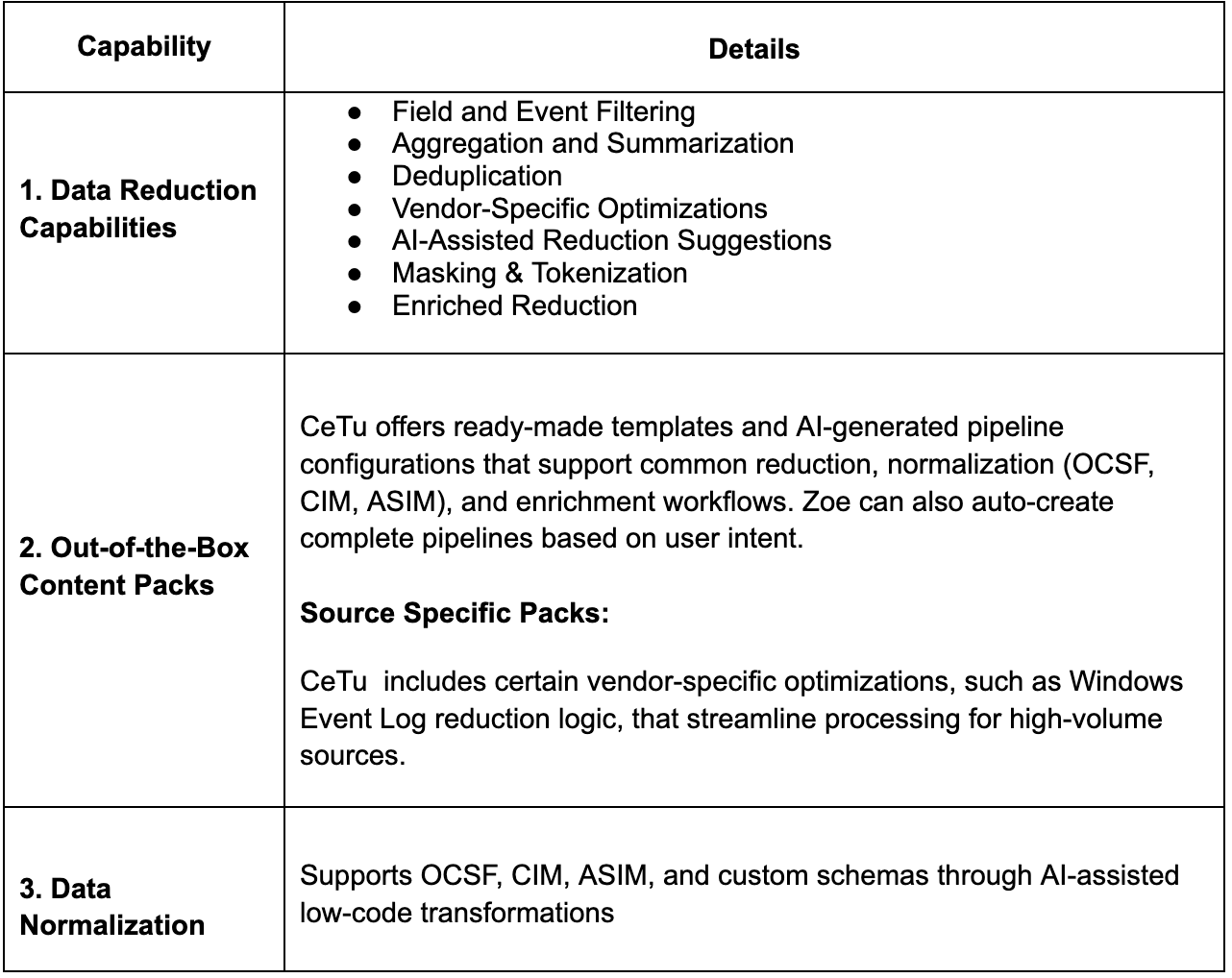


Additional Pipeline Capabilities
UI-Based Transformation Preview
The platform allows users to preview pipeline transformations within the interface, validating parsing, reduction, and normalization steps before deploying them into production.
Pipeline Building Experience
- Template-Driven Manual Authoring: Users can build pipelines by starting from ready-made templates that reflect best-practice reduction, normalization, and enrichment patterns.
- AI-Generated Pipelines: Zoe can automatically generate complete pipelines from a single user instruction, identifying gaps or inefficiencies and producing an optimized design.
AI Maturity
CeTu’s platform differentiator is the deep integration of its security-specific GenAI model across the pipeline engine, driving features like the Zoe AI assistant for routing and cost optimization, AI-assisted parsing to structure unstructured logs without reliance on complex regular expressions, and a Natural Language Builder for pipeline creation. Beyond user-facing features, CeTu VISION uses AI to perform large-scale, context-aware SIEM analysis, continuously assessing detection posture, identifying gaps, and guiding routing decisions with security context. In parallel, CeTu DEPTH applies proprietary AI-driven pattern intelligence to monitor environments over time, surface emerging issues, and recommend remediation automatically.
DEPTH differs from traditional static analytics tools by maintaining a continually expanding set of patterns based on real customer environments. These patterns include detection blind spots, event-quality gaps, and opportunities to reduce unnecessary data. This reference base allows the system to apply previously learned insights immediately, adjust optimization to each customer’s environment, and improve over time through shared learning across deployments. Because DEPTH does not need to rediscover patterns it has already identified, it lowers the cost of AI-driven analysis while improving accuracy. Each new deployment both benefits from and contributes to this shared knowledge base, creating a cumulative effect. These foundational AI systems operate continuously beneath the surface and are integral to how CeTu improves detection efficiency and visibility at scale, not just how users interact with the product.
While user feedback confirms the practical utility of these AI functions, suggesting mid-maturity, the company states their capabilities have received positive feedback from their customer base. CeTu additionally supports the operational availability of all AI features in strictly offline or on-premise deployment models, beyond SaaS deployments.
Integration Health Monitoring

Additional Capabilities
This section notes capabilities that the vendor may provide beyond pure pipeline features
Cross-System Querying
The platform provides search across SIEMs and data lakes without requiring users to write query language. Instead, it relies on structured interface actions such as breakdown, filter, and pivot. These actions automatically generate the underlying logic needed to examine patterns, isolate events, and review activity across different data sources.
Search operates directly on the connected SIEM platforms, so users can examine data without moving or duplicating it. This allows analysts to review specific event classes, compare activity across systems, and validate whether data sources are producing the expected telemetry. The platform also highlights areas where volume changes, anomalies, or gaps may require follow up.
Vision
CeTu’s stated vision is to develop an AI-driven security data framework that makes security data immediately usable and contextually meaningful. The aim is to support faster and more accurate detection and response by unifying and preparing data across systems. The company describes its approach as focusing on three areas: incorporating business context into all data streams to support informed security decisions, reducing operational effort through automation and low-code or natural language workflows, and ensuring that data is prepared to a level where security tools and language models can operate on high-fidelity, decision-ready information.
Analyst Take
Here’s where what we see as major strength and opportunity for improvement for CeTu –
Strengths:
CeTu demonstrates materially strong cost-optimization and log reduction performance, with claims supported by customer-reported results. Its deployment flexibility spans SaaS, hybrid and fully on-premises models, complemented by SOC 2 alignment. The platform integrates AI natively through the Zoe assistant and Natural Language Builder, lowering the threshold for pipeline design and iterative refinement. CeTu’s commitment to destination independence enables organizations to avoid vendor lock-in and route data across multiple analytical and storage systems. In addition, its operational telemetry provides real-time visibility, including coverage-gap insights and schema-drift detection, supporting continuous data quality assurance.
Areas to Watch:
CeTu has introduced AI capabilities that are a part of their architecture, centered on two systems: CeTu VISION, which evaluates SIEM telemetry to identify security-relevant coverage gaps, and CeTu DEPTH, which applies pattern intelligence across customer environments to surface emerging issues and recommend remediation. These systems reflect a lifecycle-oriented approach extending from data ingestion to contextual analysis and pipeline optimization. However, several areas remain for user facing AI capabilities. Security teams need clearer visibility into how the platform can influence routing decisions, data prioritization, and pipeline outcomes. Practitioner expectations for SDPP platforms have also shifted toward predictive capabilities such as anticipating schema drift, automatically rerouting based on destination health; CeTu could broaden its AI-driven insights beyond pipeline efficiency to include recommendations on data source prioritization, automated quality assurance workflows, and adaptive lifecycle management that adjusts to organizational change.

Cribl

Databahn
Panther (Datable)

Datadog

Falcon Onum (by Crowdstrike)

Observo AI, a SentinelOne Company

Realm Security

Tenzir
Tenzir, founded in 2017, raised about $3.3M in seed funding. Tenzir delivers an AI-enabled streaming data pipeline platform designed to process all telemetry across an organization’s environment. Its differentiation centers on TQL, a deterministic pipeline language, and an MCP server that converts natural-language instructions into fully generated pipelines and deployment packages. Their vision is to enable an AI-orchestrated Data Streaming Fabric that dynamically forms and adapts pipelines on demand, empowering organizations to move, transform, and validate security data in real time.
Voice of the Customer
Life Before Tenzir
The customer described a legacy log-management setup that had become increasingly complicated both in day-to-day operations and in overall cost. Their attempt to rebuild the system using open-source tooling ultimately proved unsustainable:
“We already had a solution which was quite legacy, had some problems, and wasn’t state-of-the-art. So we tried to replace it ourselves with open-source tools and came to the conclusion that it would not work, and that we should invest more in the problems of our customers and less in building the tooling to integrate system X and Y.”
The limitations of this environment pushed them toward commercial Streaming Data Pipeline solutions. Rising SIEM ingestion costs and the need to maintain consistent workflows across multiple SIEM platforms were central drivers in reassessing their architecture. As the customer put it:
“We started looking around at the solutions out there—Tenzir, Cribl, and others in that space—and in the end we came to the conclusion that Tenzir was the best match for our case.”
Most Used Capabilities Within Tenzir
The customer reported that Tenzir’s primary value lies in its ability to reduce log volume while unifying a wide range of integrations. This helped them regain control over SIEM-related costs and maintain a consistent pipeline across multiple SIEM platforms.
“It just did what we needed it to do, starting with the many integrations we required at the beginning. We are already transforming a lot of data into specific events, aggregating them, and then sending them to different SIEM solutions because we don’t have just one type. We don’t use only Elastic or Splunk or Sentinel or Google Cloud — we have different customers with different solutions.”
They emphasized that Tenzir’s normalization workflows and on-node storage materially improved investigation speed and consistency. Common enrichment and preparation steps no longer had to be recreated across different tools, and short-term storage on the node made it easier for analysts to review recent activity:
“We have storage on the node which is pretty helpful… if they [security engineers] see an incident and they want to research what happened or what this user has done in the last two days, you can — with OCSF — write some pretty nice queries which only show what has happened with that user or from that IP.”
Tenzir’s standardized enrichment flows, localized storage, and OCSF normalization streamline investigations by enabling fast, focused queries on recent user or IP activity. The customer also noted the resilience benefits of Tenzir’s architecture: keeping data and configuration on-node ensures that operations continue even if external connectivity is disrupted.
What They Would Like to See More Of
The most significant request centers on more granular role-based access control to safeguard sensitive fields within the data.
“One thing that would be really helpful for us is deeper role-based access control. Right now, there isn’t enough fine-grained control over who can access what data. We have sensitive information that shouldn’t be visible to all engineers, and some fields shouldn’t be viewable at all because they contain personal information. I’ve heard they’re already working on improvements in that area, and that would be very important from our side.”
They noted a handful of smaller operational enhancements, but access control remains the primary need moving forward:
“Beyond that, there are a few smaller operational things—customer requirements around how storage works, archiving data, optimizing compaction—that they’ve already started addressing. But those are minor compared to access control. The biggest thing we need from them is the access control.”
Architecture and Deployment Maturity
Tenzir provides a flexible deployment model that mirrors a clear separation between its cloud-based Console and on-premises Pipeline Engine. The Console functions as a SaaS control plane, while all streaming and transformation activity runs locally within the customer’s environment. For regulated or isolated settings, Tenzir can operate fully air-gapped, with both Console and Nodes deployed entirely inside the customer’s network. The architecture emphasizes deterministic, real-time processing through TQL, ensuring strict schema enforcement and data validation before telemetry is forwarded to downstream systems.
- Marketplace: AWS Marketplace is the primary distribution channel.
- MSSPs: Partnerships include DCSO, fernao magellan, and additional regional or technology.
- Compliance: No formal certifications, though Tenzir maintains internal security policies aligned with industry-standard controls.
Pricing
Ingestion-based model with fixed annual pricing for predictable budgeting.
Pricing Assistance: Tenzir does not provide a pricing calculator or automated estimator.
Data Collection and Integrations
Tenzir unifies telemetry ingestion across on-premises, cloud, and hybrid environments through a connector-driven architecture in which all processing executes locally on customer-managed nodes. The platform consolidates data collection from heterogeneous enterprise logging ecosystems and accommodates a wide spectrum of security and operational data formats.
Tenzir’s ingestion approach can be characterized across these modes:
- Pre-Built Integrations and Packages: Tenzir provides a catalog of integrations and application-specific packages that deliver ready-made TQL pipelines for sources such as AWS CloudTrail, Microsoft 365, Okta, Palo Alto, CrowdStrike Falcon, GitHub audit logs, and others. These are shipped as modular, version-controlled units that can be composed to fit customer workflows.
- Universal Connector Framework: Nodes can ingest from virtually any source using receivers for syslog, Kafka, cloud object storage (S3, GCS, Azure Blob), HTTP endpoints, databases, and low-level transport protocols including TCP/UDP, AMQP, ZeroMQ, SQS, and Pub/Sub.
- Existing Agent and Forwarder Compatibility: Tenzir is designed to integrate with customers’ existing data collectors rather than require proprietary agents. It supports Splunk UF, Elastic Beats, Fluentd, Vector, OTEL collectors, and a variety of vendor-specific forwarders.
- HTTP and API-Based Collection: The platform ingests directly from REST APIs and custom HTTP endpoints, extending coverage to SaaS services and internal applications.
Marketplace: AWS Marketplace
MSSPs: DCSO (leading European MDR provider using Tenzir for security operations infrastructure) and fernao magellan (24/7 monitoring and incident response services)
Additional partners include ticura (AI-powered threat intelligence platform), HOOP Cyber (cyber data engineering consultancy), and trustunit (Turkish cybersecurity consultancy)
Compliance: No, equivalent policies in place
Core Pipeline Capabilities
Diving deeper into core pipeline capabilities
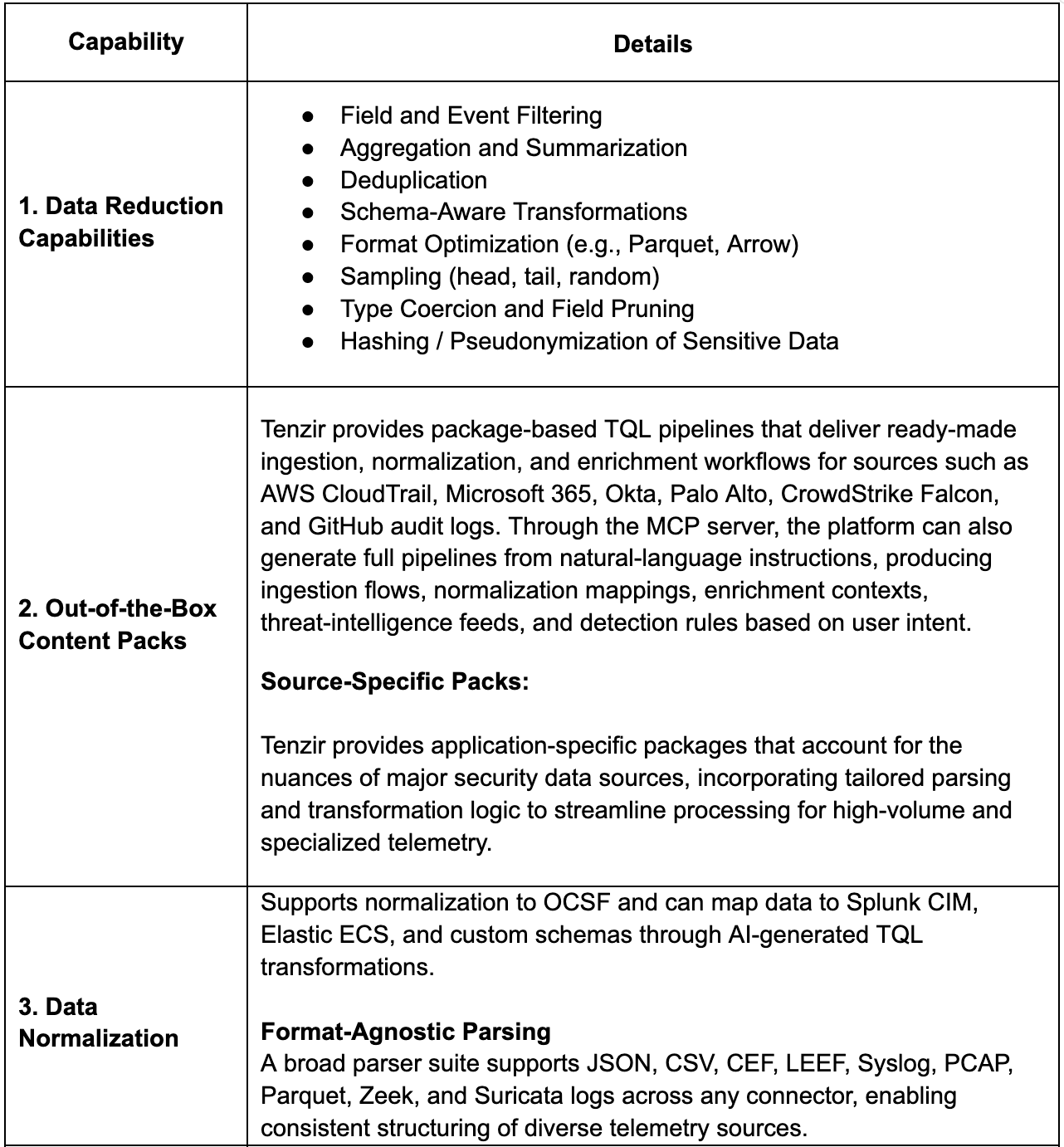

Additional Pipeline Capabilities
- Symmetric Read/Write Format Handling: Pipelines can read and write formats such as JSON, CSV, Parquet, PCAP, Zeek, CEF, LEEF, and OCSF, and can re-encode optimized data back into its original format for compatibility with downstream tools.
- Metrics and Diagnostics as Pipelines: Tenzir treats metrics and diagnostic signals as data streams, allowing users to filter, enrich, and route operational events using the same pipeline mechanics applied to production telemetry.
- Streaming OCSF Validation: Pipelines perform real-time OCSF schema validation, serving as a quality gate to ensure downstream systems receive consistently structured data.
Pipeline Building Experience
- Pipelines as Code and Operational Building Blocks: Tenzir treats pipelines as the core construct of the platform, with metrics, diagnostics, routing, enrichment, and detection all implemented as pipelines. They can be stored as code, versioned in Git, deployed through CI/CD, and forked to process raw and parsed data in parallel.
- Manual Authoring with TQL and Reusable Packages: Pipelines are built using TQL, a composable, pipe-based language inspired by Splunk’s SPL and Microsofts’ KQL. Users can assemble pipelines by chaining operators and incorporating application-specific packages that ship as independently deployable, version-controlled TQL units.
- AI-Generated Pipelines and Deployment Packages: Through the MCP server, users can describe objectives in natural language and have Tenzir generate full TQL pipelines. The AI can also produce complete deployment packages, including ingestion flows, normalization logic, enrichment contexts, threat-intelligence feeds, and detection rules.
AI Maturity
Tenzir positions AI as a foundational component of its streaming data fabric, with the MCP server enabling natural-language generation of complete TQL pipelines aligned to user intent. AI-driven schema mapping automatically translates telemetry into OCSF, Splunk CIM, Elastic ECS, and proprietary models, removing the need for manual normalization. The platform extends this automation to produce full deployment packages—spanning ingestion pipelines, enrichment contexts, threat-intelligence feeds, and detection logic.
These AI capabilities accelerate time-to-value by converting raw log samples into production-ready pipelines and enabling on-demand assembly of large, interdependent pipeline fabrics. This establishes AI as a strategic differentiator for pipeline creation, schema transformation, and dynamic fabric orchestration.
Data Privacy with AI:
- AI operates without accessing customer telemetry: Tenzir states that “sensitive security data never leaves [the] customer environment,” and this applies equally to AI-assisted functions. All ingestion, transformation, enrichment, and detection run locally on Nodes, with only metadata, metrics, and control signals exchanged with the cloud Console.
- Customer-controlled AI models (BYO-LLM): The MCP server enables AI to generate TQL pipelines through local pipeline execution, while customers supply their preferred AI model. Customers decide to which extent they share sample data with the AI provider in order to create TQL transformations.
- AI interaction limited to pipeline generation and orchestration: MCP-driven AI assists with creating pipelines, deployment packages, and troubleshooting workflows, but does not perform inference on customer telemetry or move data into external environments.
Integration Health Monitoring

Additional Capabilities
This section notes capabilities that extend beyond core pipeline functionality.
Searching
Tenzir can query data stored in cloud object storage (S3, GCS, Azure Blob) with predicate pushdown, reducing data transfer and accelerating federated search workflows.
Vision
Tenzir aims to deliver an AI-orchestrated Data Streaming Fabric in which pipelines dynamically form, optimize, and retire based on real-time needs. The Security Data Fabric represents the first expression of this model, enabling analysts to use natural language to assemble streaming architectures that manage ingestion, normalization, enrichment, and detection across distributed environments.
Analyst Take
Here’s where what we see as major strength and opportunity for improvement for Tenzir –
Strengths
Tenzir’s strengths center on deterministic, standards-aligned pipelines and a design philosophy that treats pipeline reliability as a core engineering requirement. TQL enforces structure and validation in stream, which reduces downstream drift and noisy normalization issues. This is especially valuable for teams standardizing on OCSF or operating in regulated environments. The platform’s AI focus is on pipeline creation rather than inference. MCP turns natural language goals into complete TQL pipelines and deployment bundles, closing the long-standing gap between messy sample logs and production-ready pipelines. Tenzir also adopts a local-first execution model with an air-gapped option that keeps processing and control entirely inside the customer perimeter. The platform supports broad integrations without requiring proprietary agents, which lowers onboarding friction.
Areas to Watch
Key areas to watch include the depth of access control, where customers want more granular RBAC and field-level protections for sensitive data. Schema drift detection is another gap. Fast-moving SaaS sources require proactive alerts and assisted remediation to keep pipelines stable as formats evolve. Compliance maturity will matter for enterprise buyers because the absence of formal compliance certifications extends vendor review cycles and slows procurement. Expectations for AI pipeline capabilities are increasing as well. Buyers in regulated sectors will expect audit trails, prompt-to-code traceability, and structured change control for AI-generated pipelines. Package quality and lifecycle management will be evaluated closely, especially the speed at which new fields and vendor API changes are supported. Marketplace and MSSP motions are still developing, and large customers often require multi-cloud purchasing paths and clear shared responsibility models.

VirtualMetric
The core strength of VirtualMetric is their deep integration with Microsoft services. VirtualMetric positions itself as a security telemetry pipeline built for enterprises and MSSPs that need centralized, cloud-managed control with data processing kept entirely within the customer’s environment. The platform was built with MSSP support in mind to cater for centralized multi-tenancy support.
Voice of the Customer
We interviewed a customer of VirtualMetric about their experience with the platform. Here is what they said –
Life before VirtualMetric
Before VirtualMetric, the security team struggled with costly and rigid log ingestion into Microsoft Sentinel. Third-party logs, especially from high-volume sources like Palo Alto, drove up costs due to flat ingest pricing. “You paid five dollars per gigabyte you ingest,” the security leader noted. Limited control over routing also made it hard to manage noisy data: “We decided to ignore network logs for a long while because it’s just too noisy, it’s too expensive.” Deploying Linux-based forwarding also placed an operational burden on smaller customers, many of whom lacked the internal expertise to manage it.
Most used capabilities within VirtualMetric
Routing flexibility and centralized pipeline management were top priorities for this organization. “We really value the content packs… we can also reuse filtering. So if we decide to do Palo Alto filtering for one customer, all the other customers also immediately benefit.” While cost reduction is a clear value, the leader emphasized that “I would value that even higher than the actual cost reduction.” Features like filtering out null-value fields helped lower ingest without sacrificing fidelity: “From a cost perspective, I think it’s almost a no-brainer.”
What they’d like to see more of
The organization adopted VirtualMetric not just for features, but for the ability to influence roadmap direction. “We liked the fact that they were still a new company… we already saw stuff we proposed come into the product.” Key asks include CI/CD integration (“We run SIEM-as-code quite seriously”) and stronger multi-tenancy controls for MSSPs. The leader also pointed to real-time threat intel matching as a valuable addition. Looking forward, they see VirtualMetric remaining focused on telemetry infrastructure rather than competing with the SIEM: “The SIEM is also a single place of truth.” Instead, he sees VirtualMetric filling critical gaps: “Microsoft has their hands full developing AI features… they are neglecting the logging pipeline a little bit. That’s why VirtualMetric came at the right time.”
Architecture and Deployment Maturity
VirtualMetric separates the control plane (Console) and data plane (Pipeline Engine) to support flexible deployment models. The management console is delivered as SaaS for centralized fleet oversight, while the pipeline engine runs entirely in the customer’s environment, whether on premises or in their own cloud.
For air-gapped or isolated environments, a Self-Managed mode for Console is available where no data is sent to the vendor’s cloud. The underlying architecture incorporates a write-ahead log and vectorized processing to support high-throughput ingestion and ensure zero data loss.
One of their core differentiators is their architecture. The pipeline engine is built on a write-ahead log (WAL) and vectorized processing model, which means logs are durably written to disk before processing begins, minimizing the risk of data loss. Once written, the data is processed in parallel across all CPU cores, enabling high throughput and low latency even under heavy workloads.
- Marketplace: Azure Marketplace and Microsoft Security Store, with AWS and Google Cloud support in progress.
- MSSPs: The company is also exploring partnerships with OVHCloud and Scaleway to meet European sovereignty requirements
- Compliance: SOC 2 Type II and ISO 27001.
Pricing
Ingestion based licensing model.
Pricing Assistance:
- Public Licensing: Pricing details publicly available on its website.
- Average: Usage is calculated based on a 7-day daily average to prevent short-term data spikes from triggering unexpected costs.
- ROI Calculator: The vendor also offers an ROI calculator to help prospective customers estimate potential time and cost savings.Consumption-based model
Data Collection and Integrations
VirtualMetric offers flexible data collection methods.
- Smart Agent (Remote and Direct Deployment): VirtualMetric offers a proprietary Smart Agent that supports remote, no-install collection from Windows, Linux, Solaris, and AIX systems. Enterprises can also opt to deploy the agent locally where needed.
- Syslog and Network Protocols: Ingests data from standard protocols including Syslog, NetFlow/IPFIX, Cisco eStreamer, TCP, UDP, and HTTP, enabling integration with a wide range of network and security appliances.
- Forwarders and Event Streams: Supports ingestion from streaming platforms like Kafka, along with common log forwarders.
- OpenTelemetry Collectors: Compatible with OTEL collectors to support standardized, vendor-neutral telemetry collection across environments.
- API-Based and Managed Identity Integration: Includes support for agentless API-based integrations. For Microsoft Sentinel, VirtualMetric uses Managed Identity to avoid token rotation issues during connector operation.
Total number of integrations out of box: 45+ direct vendor integrations but a larger number when supported collection methods are taken into account.
Core Pipeline Capabilities


Additional Pipeline Capabilities
- Advanced Data Deduplication: A new staged-routing and commit-processor pattern that simplifies multi-tier data pipelines by automatically selecting and committing only the highest-quality normalized log format, eliminating duplication, complexity, and conditional logic.
- Extensive Drag and Drop Library: Vendor claims they offer over 150 purpose-built processors, enabling users to build complex pipelines through a drag-and-drop interface without writing code.
- Transformation and Optimization: Processors like Compact remove empty or placeholder fields, while Enforce-Schema ensures incoming data aligns with the expected structure.
- AI and Text Processing: AI-based and text processing modules classify and extract insights from unstructured logs, improving visibility and enabling downstream analytics.
- Codeless Pipeline Design: The processor framework is meant to allow teams to design, test, and deploy pipelines quickly.
- Observability Use Case: VirtualMetric DataStream is designed as a telemetry pipeline for both observability and security use cases, with a focus on data sovereignty and operational scale.
Pipeline Building Experience
- Elastic-Compatible Pipeline Syntax and Prebuilt Pipelines: VirtualMetric DataStream supports Elastic Ingest Pipeline syntax, allowing teams to reuse existing Elastic pipelines without modification. It also provides access to over 300 prebuilt pipelines for common sources and use cases.
- Drag-and-Drop Visual Pipeline Builder (Coming soon): A new visual debugger and builder is set to launch soon. This feature will allow users to design, test, and troubleshoot pipelines using an intuitive drag-and-drop interface, reducing reliance on manual configuration.
- AI-Assisted Pipeline Creation (Coming Soon): VirtualMetric plans to release an AI Copilot feature that lets users describe pipeline goals in natural language. The system will translate those inputs into processors and flow logic, streamlining the creation process for teams that want to move faster without deep technical setup.
AI Maturity
VirtualMetric DataStream uses AI processors that integrate with OpenAI, Azure OpenAI, and Anthropic Claude. These processors allow users to classify logs, extract entities, and generate summaries by applying user-defined prompts directly within the data stream. These functions also help process unstructured log data and provide structure and context before routing.
The platform also uses AI to assist with data quality by identifying misconfigurations, classifying event types, and detecting anomalies. This supports more accurate filtering and helps reduce alert volume. VirtualMetric plans to introduce an AI Copilot feature that will let users build pipelines using natural language input. This capability is intended to simplify pipeline creation by translating user intent into configured processors and flows. AI is also applied to improve routing decisions and threat context enrichment, supporting earlier detection and more efficient data distribution across SIEM and data lake environments.
Data Privacy with AI:
- No data collection: No customer data is sent to VirtualMetric’s cloud. All data processing happens entirely within the customer’s environment (on-prem or private cloud), ensuring full data ownership and control.
- AI processors run within the customer environment: Ensuring that data stays local even when using third-party AI services for classification or summarization.
Integration Health Monitoring
Vision
VirtualMetric’s stated vision is to serve as the central telemetry and data management layer for both security and observability use cases. Rather than replacing SIEMs or data lakes, the platform aims to decouple data collection, normalization, and optimization from the analytics layer. They are also investing in real-time detection and edge intelligence to support context-aware routing, enabling teams to process all telemetry types and forward only relevant data. The long-term goal is to become the foundation for an open, vendor-agnostic Security and Observability Data Fabric.
Analyst Take
Here’s where what we see as major strength and opportunity for improvement for VirtualMetric
Strengths
VirtualMetric offers a deterministic, rule-based reduction model that helps reduce ingestion costs without risking detection quality. Its deep Microsoft integration, covering Sentinel, Sentinel data lake, ADX, Blob Storage, DCR autodiscovery, and ASIM schema alignment, removes manual routing overhead and suits MSSPs managing multiple tenants. Processing happens entirely in the customer’s environment, with support for SaaS, self-managed, and air-gapped setups. Backed by a write-ahead log and vectorized engine, the platform delivers high-throughput performance without relying on vendor cloud infrastructure. For teams prioritizing control, Microsoft native alignment, and operational clarity, VirtualMetric is a strong fit. The use of a write-ahead log and vectorized processing enables high-throughput pipelines, supporting both performance and resilience. Overall, VirtualMetric offers a strong operational foundation and a clear roadmap. Teams seeking precision, Microsoft-native alignment, and operational independence will find the platform compelling.
Areas to Watch
VirtualMetric currently lacks full integration health visibility across all data sources, creating potential blind spots for security teams until broader monitoring arrives. Certain advanced pipeline features like integration health monitoring beyond VirtualMetric’s own Smart Agent, and automated coverage gap detection are still in development. The platform does not provide formalized coverage gap analysis to show missing telemetry across data sources or ATT&CK techniques, which limits visibility into detection blind spots. Looking ahead, areas worth watching include their planned Sigma and YARA based edge detection capabilities in Q1 2026, the evolution of their multi cloud data lake strategy as major providers rapidly expand their native lakes, and their positioning in air gapped and sovereignty focused markets where self managed deployments and European cloud partnerships could be differentiators.


